
Lab 0
Writing webget
要求使用TCPSocket和Address类实现get_URL函数。get_URL的功能是向指定的host和path发送GET请求,以抓取页面。可以参考Sponge: TCPSocket Class Reference (cs144.github.io)中的示例来了解类和方法的使用。
HTTP 请求报文中需要的头部字段和值分别为:
Connection:Close,用于通知host不必等待client后续发送请求,在接收到该请求后发送响应。
Host: host表示被请求的主机URL
在请求头和请求数据之间存在一个空行,而GET请求没有请求数据,因此以空行结尾。
void get_URL(const string &host, const string &path) {
TCPSocket sock;
sock.connect(Address(host, "http"));
sock.write("GET " + path + " HTTP/1.1\r\nHost: " + host + "\r\nConnection: close\r\n\r\n");
sock.shutdown(SHUT_WR); //发送完毕,关闭读写
while (!sock.eof()) {
cout << sock.read();
}
sock.close();
}
An in-memory reliable byte stream
要求实现可靠的字节流的抽象,在输入端写入字节而在输出端按照相同顺序读出字节。实质上相当于一个带有容量限制的队列,发送方从末尾写,接收方从头部读出,已经被读出的字节从队列中删除,以释放内存空间。
ByteStream定义如下:
class ByteStream {
private:
std::string byte_stream = "";
size_t _capacity = 0;
size_t bytes_written_count = 0;
size_t bytes_read_count = 0;
bool _error{}; //!< Flag indicating that the stream suffered an error.
bool input_end = false;
初始时byte_stream定义为空字符串,_capacity表示ByteStream容量,bytes_written_count和bytes_read_count分别表示已经向ByteStream中写入和读出的字符数,均定义为size_t类型,初始化为0。input_end为true表示输入已经结束,初始为false。
byte_stream.cc中成员函数定义如下:
ByteStream::ByteStream(const size_t capacity) {
_capacity = capacity;
}
// capacity - byte_stream.size() = remaining_capacity
size_t ByteStream::write(const string &data) {
size_t written = 0;
if (data.size() <= remaining_capacity()) {
written = data.size();
byte_stream += data;
} else {
written = remaining_capacity();
byte_stream += data.substr(0, written);
}
bytes_written_count += written;
return written;
}
//! \param[in] len bytes will be copied from the output side of the buffer
string ByteStream::peek_output(const size_t len) const {
string res;
if (byte_stream.size() <= len) {
res = byte_stream;
} else {
res = byte_stream.substr(0, len);
}
return res;
}
//! \param[in] len bytes will be removed from the output side of the buffer
void ByteStream::pop_output(const size_t len) {
if (byte_stream.size() <= len) {
bytes_read_count += byte_stream.size();
byte_stream = "";
} else {
bytes_read_count += len;
byte_stream = byte_stream.substr(len, byte_stream.size() - len);
}
}
//! Read (i.e., copy and then pop) the next "len" bytes of the stream
//! \param[in] len bytes will be popped and returned
//! \returns a string
std::string ByteStream::read(const size_t len) {
std::string res = peek_output(len);
pop_output(len);
return res;
}
void ByteStream::end_input() { input_end = true; }
bool ByteStream::input_ended() const { return input_end; }
size_t ByteStream::buffer_size() const { return byte_stream.size(); }
bool ByteStream::buffer_empty() const { return byte_stream.empty(); }
bool ByteStream::eof() const { return buffer_empty() && input_ended(); }
size_t ByteStream::bytes_written() const { return bytes_written_count; }
size_t ByteStream::bytes_read() const { return bytes_read_count; }
size_t ByteStream::remaining_capacity() const { return _capacity - byte_stream.size(); }
其中buffer_size和buffer_empty分别表示缓冲区的大小和缓冲区是否为空,buffer即ByteStream类中的byte_stream字符串。读操作分为了两个步骤:先peek后pop,根据测试用例,在peek时应该随之更新bytes_read_count,而不能在完成一个完整的read操作后再更新。在向byte_stream中写入字节时,应该判断是否超出了缓冲区的容量,超出容量的部分直接截断,而无需缓存。
如何判断是否读到了eof?参照EOF的定义,When the reader has read to the end of the stream, it will reach “EOF” (end of file)。只有当输入方已经不再输入(即input_ended == true)并且缓冲区中的数据已经全部读出(即buffer_empty==true)时,输出端读到了字节流的末尾。
Lab 1
要求将乱序的子串重排序,合并成连续的顺序正确的ByteStream。ByteStream中的每个字节都有唯一的下标,下标规定了字节的先后顺序。字节实际上分成了两部分:ByteStream中已经排好序的连续子串和unassembled_bytes中尚未排好序 的子串。对于一个起始下标为index的子串,只有当index-1对应的字节已经写入到ByteStream中后,才能够将index对应的子串加入到ByteStream中。因此应该选择有序的数据结构,考虑到重复下标对应的字节仅应保存一次,在合并不同的子串时需要遍历整个数据结构,因此采用set作为unassembled_bytes。
StreamReassembler类定义如下:
struct block {
std::string data;
size_t index;
bool eof;
block(std::string &s, bool flag, size_t idx) : data(s), index(idx), eof(flag) {}
bool operator<(const block &b) const {
return index < b.index;
}
};
class StreamReassembler {
private:
std::set<block> unorder_bytes = std::set<block>();
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
// _capacity = _output.size() + unassembled size
size_t next_index = 0;
size_t unassembled_count = 0;
bool _eof = false;
void merge_block(const block &b);
......
push_substring的处理流程:首先判断待插入的子串是否已经写入过ByteStream或是超出capacity的限制,如果存在与ByteStream重叠或超出限制的部分,则对子串进行截取。如果子串刚好可以写入ByteStream,则调用write方法,并递归检查unassembled_bytes中是否有可以加入到ByteStream中的block。如果子串与ByteStream不连续,则将子串与unassembled_bytes中的block进行合并,等待后续的插入。如果eof为true,并且参数中的data没有超出容量限制,表示已经读取到了文件末尾,将_eof标志设置为true。如果_eof为true并且不存在乱序的子串,则调用end_input()方法表示输入结束。如果eof为true但data超出容量限制从而丢弃了data中靠后的部分,此时EOF并未加入到unassembled_bytes或ByteStream中,_eof保持不变以等待重传。push_substring代码如下:
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
size_t right = index + data.size();
size_t bound = next_index + _capacity - _output.buffer_size();
if (right <= next_index) {
if (eof) _eof = true;
if (_eof && empty()) _output.end_input();
return;
}
if (index >= bound) return;
bool end = eof;
std::string substring = std::move(data);
if (right > bound) {
substring = substring.substr(0, substring.size() - (right - bound));
end = false;
}
if (index <= next_index) {
substring = substring.substr(next_index - index, substring.size() - (next_index - index));
next_index += substring.size();
_output.write(substring);
if (end) _eof = true;
while (!unorder_bytes.empty()) {
auto iter = unorder_bytes.begin();
if ((*iter).index <= next_index) {
auto str = (*iter).data;
bool flag = (*iter).eof;
size_t idx = (*iter).index;
unorder_bytes.erase(*iter);
unassembled_count -= str.size();
push_substring(str, idx, flag);
continue;
}
break;
}
} else {
merge_block(block(substring, end, index));
}
if (_eof && empty()) _output.end_input();
}
void StreamReassembler::merge_block(const block &b) {
for (auto iter = unorder_bytes.begin(); iter != unorder_bytes.end(); iter++) {
if (b.index + b.data.size() < (*iter).index) {
unorder_bytes.insert(b);
unassembled_count += b.data.size();
return;
} else if (b.index < (*iter).index && b.index + b.data.size() >= (*iter).index
&& b.index + b.data.size() < (*iter).index + (*iter).data.size()) {
size_t index = b.index;
std::string str = b.data.substr(0, (*iter).index - b.index) + (*iter).data;
bool eof = (*iter).eof || b.eof;
unassembled_count -= (*iter).data.size();
unassembled_count += str.size();
unorder_bytes.erase(*iter);
unorder_bytes.insert(block(str, eof, index));
return;
} else if (b.index >= (*iter).index && b.index + b.data.size() <= (*iter).index + (*iter).data.size()) {
return;
} else if (b.index <= (*iter).index && b.index + b.data.size() >= (*iter).index + (*iter).data.size()) {
unassembled_count -= (*iter).data.size();
unorder_bytes.erase(*iter);
merge_block(b);
return;
} else if (b.index >= (*iter).index && b.index <= (*iter).index + (*iter).data.size()
&& b.index + b.data.size() > (*iter).index + (*iter).data.size()) {
size_t index = (*iter).index;
std::string str = (*iter).data.substr(0, b.index - (*iter).index) + b.data;
bool eof = (*iter).eof || b.eof;
unassembled_count -= (*iter).data.size();
unorder_bytes.erase(*iter);
merge_block(block(str, eof, index));
return;
}
}
unorder_bytes.insert(b);
unassembled_count += b.data.size();
}
Lab 2
实现64bit的下标和32bit序列号之间的转换

主要是实现两个方法:
//! Transform a 64-bit absolute sequence number (zero-indexed) into a 32-bit relative sequence number
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn);
//! Transform a 32-bit relative sequence number into a 64-bit absolute sequence number (zero-indexed)
uint64_t unwrap(WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint);
从64位转换为32位比较简单,直接截取低32位即可。从32位转换为64位比较复杂,因为一个32位的序列号可能会对应无数个64位的下标,因此需要使用checkpoint作为锚定点,选择与数轴上checkpoint距离最近的作为下标。参数中的isn是产生的初始序列号,n是需要转换到64位的序列号。其中
$ n = (isn + index) \& 0xFFFFFFFF $
显然,index的低32位与 $n - isn + (1ll « 32)$的低32位相同。
设$ tmp = n - isn + (1ll « 32) \&0xFFFFFFFF $。那么问题就转变成了,寻找与checkpoint在数轴上距离最近的index,使得$ (index - tmp) \% (1ll « 32) = 0$。
令$tmp = tmp + 1ll«32, if tmp < checkpoint $,
则$index = min(tmp, tmp - 1ll « 32)$.
wrap和unwrap代码如下:
//! Transform an "absolute" 64-bit sequence number (zero-indexed) into a WrappingInt32
//! \param n The input absolute 64-bit sequence number
//! \param isn The initial sequence number
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn) {
return WrappingInt32(n + isn.raw_value());
}
//! Transform a WrappingInt32 into an "absolute" 64-bit sequence number (zero-indexed)
//! \param n The relative sequence number
//! \param isn The initial sequence number
//! \param checkpoint A recent absolute 64-bit sequence number
//! \returns the 64-bit sequence number that wraps to `n` and is closest to `checkpoint`
//!
//! \note Each of the two streams of the TCP connection has its own ISN. One stream
//! runs from the local TCPSender to the remote TCPReceiver and has one ISN,
//! and the other stream runs from the remote TCPSender to the local TCPReceiver and
//! has a different ISN.
uint64_t unwrap(WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) {
uint64_t tmp = 0;
uint64_t tmp1 = 0;
if (n - isn < 0) {
tmp = uint64_t(n - isn + (1l << 32));
} else {
tmp = uint64_t(n - isn);
}
if (tmp >= checkpoint)
return tmp;
tmp |= ((checkpoint >> 32) << 32);
while (tmp <= checkpoint)
tmp += (1ll << 32);
tmp1 = tmp - (1ll << 32);
return (checkpoint - tmp1 < tmp - checkpoint) ? tmp1 : tmp;
}
实现TCP receiver
receiver的功能主要有三个部分:1)接收对端发送的segment;2)使用StreamResassembler重排成ByteStream;3)计算ackno和窗口大小。
TCPReceiver类定义如下:
class TCPReceiver {
//! Our data structure for re-assembling bytes.
StreamReassembler _reassembler;
//! The maximum number of bytes we'll store.
size_t _capacity = 0;
WrappingInt32 isn = WrappingInt32(0);
// _ackno = absolute sequence number + 1
// ackno = wrap(_ackno + isn)
uint64_t _ackno = 0;
bool _syn = false;
bool _fin = false;
...
}
receiver每次接收到新的segment时,调用segment_received方法,如果此时:
- 连接尚未建立
- 如果SYN置位,表明收到了第一次握手,初始化ISN和_ackno
- 否则,表明收到了过期的segment,直接丢弃
- 连接已经建立
- 如果syn置位,表明收到了冗余的握手报文,直接丢弃
- 如果fin置位,表明收到了第一次挥手,发送方不再发送报文。如果此前收到的报文均已按序排列,则调用end_input()表示设置EOF
- 否则,将payload交给StreamReassembler
_ackno是如何变化的?
- 连接建立时,SYN报文会占用1个seqno,因此_ackno应该初始化为1
- 连接建立后,如果报文中携带的payload可以加入到ByteStream,则_ackno = _ackno + payload.size + unassembled_bytes中加入ByteSteam的size
- 收到fin报文时,如果前面还有未排好序的报文,则_ackno保持不变。否则,由于fin报文本身占用一个seqno,因此_ackno + 1
对应的代码实现如下:
void TCPReceiver::segment_received(const TCPSegment &seg) {
if (seg.header().syn) {
if (_syn) return;
_syn = true;
isn = seg.header().seqno;
_ackno = 1;
}
if (!_syn) return;
bool eof = false;
if (seg.header().fin) {
_fin = true;
eof = true;
}
size_t index = 0;
if (!seg.header().syn) {
index = unwrap(seg.header().seqno - 1, isn, _reassembler.stream_out().buffer_size());
} else {
index = unwrap(seg.header().seqno, isn, _reassembler.stream_out().buffer_size());
}
std::string payload = seg.payload().copy();
size_t stream_size = _reassembler.stream_out().buffer_size();
_reassembler.push_substring(payload, index, eof);
_ackno += _reassembler.stream_out().buffer_size() - stream_size;
if (_fin && _reassembler.unassembled_bytes() == 0)
_ackno++;
}
optional<WrappingInt32> TCPReceiver::ackno() const {
if (!_syn) {
return {};
} else {
return wrap(_ackno, isn);
}
}
size_t TCPReceiver::window_size() const { return _capacity - _reassembler.stream_out().buffer_size(); }
Lab 3
Lab 3的任务是实现TCPSender,按照一定的顺序从ByteStream中读取字节组成TCP segment,并发送到TCPReceiver,根据TCPReceiver响应报文维护发送窗口,保存已发送未确认的TCPsegment并在超时未收到确认时重新发送。
如何判断某个segment是否超时
TCP周期性调用TCPSender::tick()方法,表示距离上次调用经过的时间。当TCPSender初始化时,指定重发时间RTO的初始值,当某个TCPSegment经过RTO仍未收到来自receiver的确认时,重发第一个未确认的TCPSegment。
要求实现一个timer,用作定时器,由TCPSender::tick调用。定时器需要实现如下功能:
- 当发送一个长度非0的segment时,如果timer此时不在运行,则使用当前的RTO初始化开始计时。
- 当调用tick,并且timer超时时:
- 重发最早的未被确认的segment。
- 如果发送窗口大小不为0:
- consecutive_retransmissions+1,表示连续出现的重发次数,当重发次数过多时,表明网络状况太差,交给后面的TCPConnection中断连接。
- RTO加倍,即指数退避算法,避免由于连续的重发加大网络负载。
- 使用新的RTO重置定时器,重新开始计时
- 当收到来自接收方的确认时:
- 将RTO设置为初始值
- 如果此时还有未被确认的segment,重置定时器
- 重置consecutive_transmissions为1
结合以上规则,设计了如下Timer类:
class Timer {
private:
size_t _rto = 0;
size_t elapsed_time = 0;
bool running = false;
public:
Timer() {}
void enable(size_t rto) { if (!running) { running = true; _rto = rto; } }
void disable() { running = false; elapsed_time = 0; }
void tick(const size_t ms_since_last_tick) { elapsed_time += ms_since_last_tick; }
bool is_timeout() { return elapsed_time >= _rto; }
void reset(size_t new_rto = 0) { running = true; _rto = new_rto; elapsed_time = 0; }
};
对应的TCPSender::tick的实现:
//! \param[in] ms_since_last_tick the number of milliseconds since the last call to this method
void TCPSender::tick(const size_t ms_since_last_tick) {
if (_segments_unacknowledged.empty())
return;
_timer.tick(ms_since_last_tick);
if (_timer.is_timeout()) {
_segments_out.push(_segments_unacknowledged.front());
if (_window_size > 0) {
_retransmission_timeout *= 2;
_consecutive_retransmissions++;
}
_timer.reset(_retransmission_timeout);
}
}
要注意的一点是,在TCPSender类中,构造函数参数retx_timeout类型为uint16_t,而如果Timer中的_rto和elapsed_time也被设计为uint16_t,随着超时次数增大,RTO不断加倍,会引起溢出问题,从而导致在本没有超时的情况下超时,因此将类型统一设置为size_t来规避溢出。
TCPSender实现
在需要发送segment时,会调用fill_window方法,该方法从ByteStream中尽可能多地读取字节作为segment的载荷。难点在于如何处理发送窗口与序列号的关系。
首先,发送窗口大小由接受方指定,为已发送未确认的字节数与剩余可发送的字节数之和。而这个窗口的大小不仅仅针对载荷,SYN和FIN两个报文也各占1字节空间,因此在构建报文时需要考虑SYN和FIN两个标志位。具体地说,应该按照SYN->payload->FIN的顺序,依次判断当前发送窗口中是否还有空余位置。
其次,当window_size为0时,文档中说”fill window method should act like the window size is one”.原因是在receiver对上一次报文的响应中通知sender接收窗口为0,此时如果sender不再向receiver发送报文,则即使receiver更新了自己的接收窗口,但由于不再接收到新的报文,也不会再向sender发送响应通知这一更新,从而导致二者相互等待的现象出现。但是,如果此时仍有已发送而未确认的报文存在,则无需再次发送。
再次,FIN报文的处理。只有当第一次读到stream尾部时,才应当将报文的FIN标志位置为true。如果后续调用fill_window,由于此时ByteStream已经读到了EOF,而此前已经发送过FIN报文,无论是否超时,都不应该由fill_window方法再次发送一次FIN报文。因此需要跟踪FIN报文的状态来避免再次发送。
最后,fill_window方法应当何时结束?TCP要求在发送窗口允许的情况下尽可能多地发送报文,而由于网络的限制,payload不能无限制的增长,因此对于超长的报文,需要分段来多次完成发送。当length_in_sequence_space为0时,表明当前的报文发送完毕,方法返回。
为了代码简洁,从fill_window中拆出了send_segment方法,代码如下:
bool TCPSender::send_segment(TCPSegment &segment, const size_t length) {
if (_next_seqno == 0)
segment.header().syn = true;
segment.header().seqno = wrap(_next_seqno, _isn);
if (length < size_t(segment.header().syn))
return false;
// MAX_PAYLOAD_SIZE limits payload only.
std::string payload = _stream.read(min(TCPConfig::MAX_PAYLOAD_SIZE, length - segment.header().syn));
segment.payload() = Buffer(std::move(payload));
if (!_fin && _stream.eof() && length > segment.length_in_sequence_space()) {
_fin = true;
segment.header().fin = true;
}
if (segment.length_in_sequence_space() == 0)
return false;
else {
_next_seqno += segment.length_in_sequence_space();
_bytes_in_flight += segment.length_in_sequence_space();
_segments_out.push(segment);
_segments_unacknowledged.push(segment);
return !_stream.eof();
}
}
// 长度非0的segment发送后,如果timer未启动,启动timer
void TCPSender::fill_window() {
size_t fill_window = 0;
// if receiver announce a window size of zero, fill_window method should act like the window_size is one
if (_window_size == 0) {
if (_bytes_in_flight == 0) {
TCPSegment segment;
send_segment(segment, 1);
} else
return;
} else {
while (true) {
TCPSegment segment;
if (_window_size > _bytes_in_flight)
fill_window = _window_size - _bytes_in_flight;
else
fill_window = 0;
if (!send_segment(segment, fill_window))
break;
}
}
if (!_segments_unacknowledged.empty())
_timer.enable(_retransmission_timeout);
}
在接收到来自receiver的响应时,调用ack_received方法。TCP采用累计确认,即序列号范围在ackno之前的报文均得到确认。但是,由于网络拥塞等状况的出现,可能会收到若干乱序的确认报文。如果收到的确认号之前已经被确认过,或者确认号大于连接发送过的最大的序列号,该确认报文就应该被丢弃以避免干扰连接。对应的代码如下:
//! \param ackno The remote receiver's ackno (acknowledgment number)
//! \param window_size The remote receiver's advertised window size
void TCPSender::ack_received(const WrappingInt32 ackno, const uint16_t window_size) {
uint64_t _ackno = unwrap(ackno, _isn, _next_seqno);
_window_size = window_size;
if (_ackno > _next_seqno || _ackno <= _next_seqno - _bytes_in_flight)
return;
bool reset = false;
// look through its collection of outstanding segments and remove any that have now been fully acknowledged
while (!_segments_unacknowledged.empty()) {
TCPSegment segment = _segments_unacknowledged.front();
if (unwrap(segment.header().seqno, _isn, _next_seqno) + segment.length_in_sequence_space() <= _ackno) {
_bytes_in_flight -= segment.length_in_sequence_space();
_segments_unacknowledged.pop();
reset = true;
} else
break;
}
if (reset) {
_retransmission_timeout = _initial_retransmission_timeout;
_consecutive_retransmissions = 0;
if (!_segments_unacknowledged.empty())
_timer.reset(_retransmission_timeout);
else
_timer.disable();
}
}
TCPSender类中数据成员定义如下:
class TCPSender {
private:
//! our initial sequence number, the number for our SYN.
WrappingInt32 _isn;
//! outbound queue of segments that the TCPSender wants sent
std::queue<TCPSegment> _segments_out{};
std::queue<TCPSegment> _segments_unacknowledged{};
//! retransmission timer for the connection
size_t _initial_retransmission_timeout;
size_t _retransmission_timeout;
//! outgoing stream of bytes that have not yet been sent
ByteStream _stream;
//! the (absolute) sequence number for the next byte to be sent
uint64_t _next_seqno{0};
Timer _timer{};
size_t _window_size = 1;
size_t _bytes_in_flight = 0;
int _consecutive_retransmissions = 0;
bool _fin = false;
...
Lab 4
Lab4要求实现一个TCPConnection类,主要功能是封装TCPSender和TCPReceiver,构建TCP的有限状态机。这个实验相比于前面几个实验多了很多的细节逻辑,并且很多地方需要修改前面的代码,因此难度相比于前几个大幅提升。
TCPConnection各种状态迁移主要是按照如下三幅图来做:
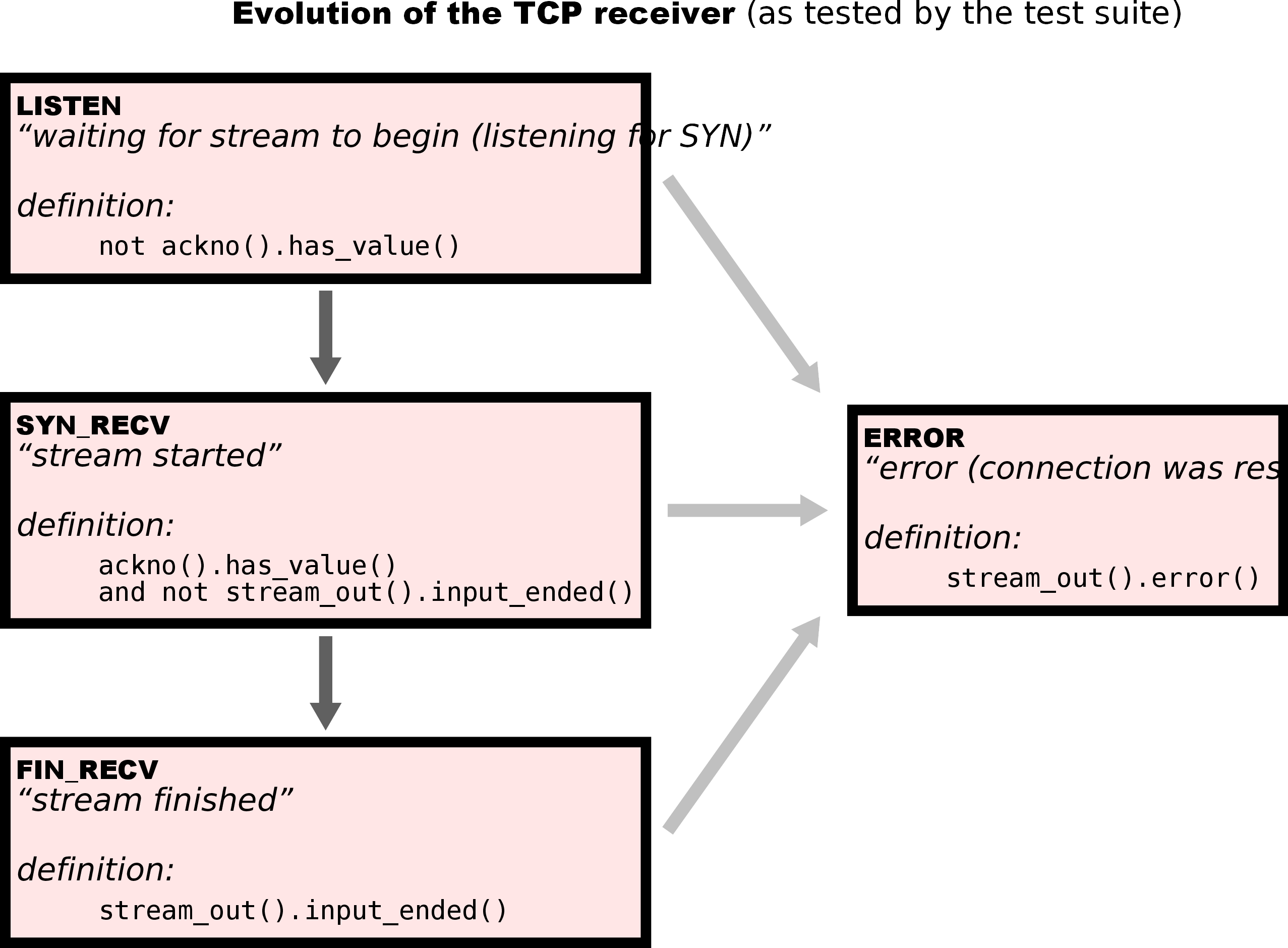
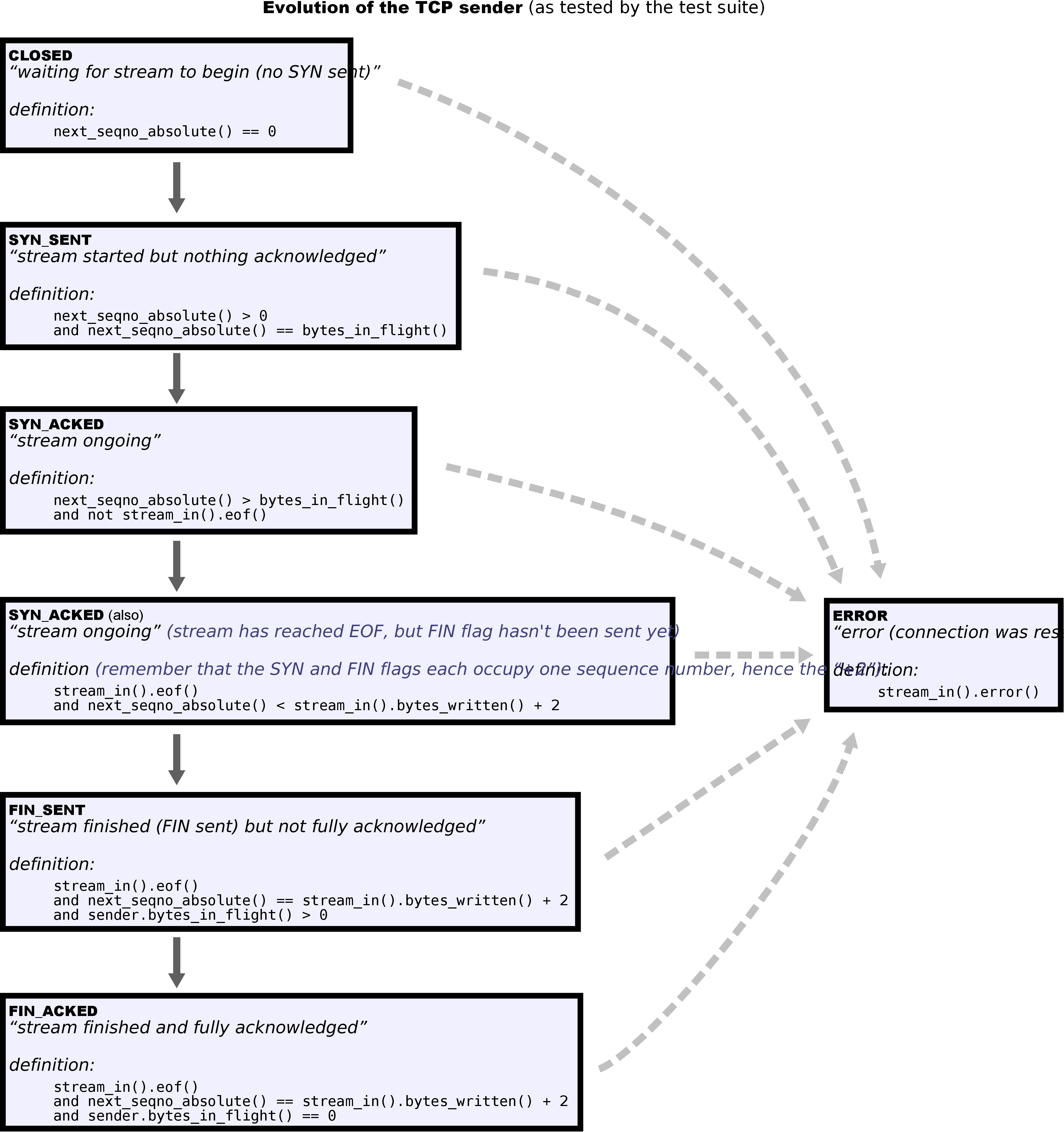
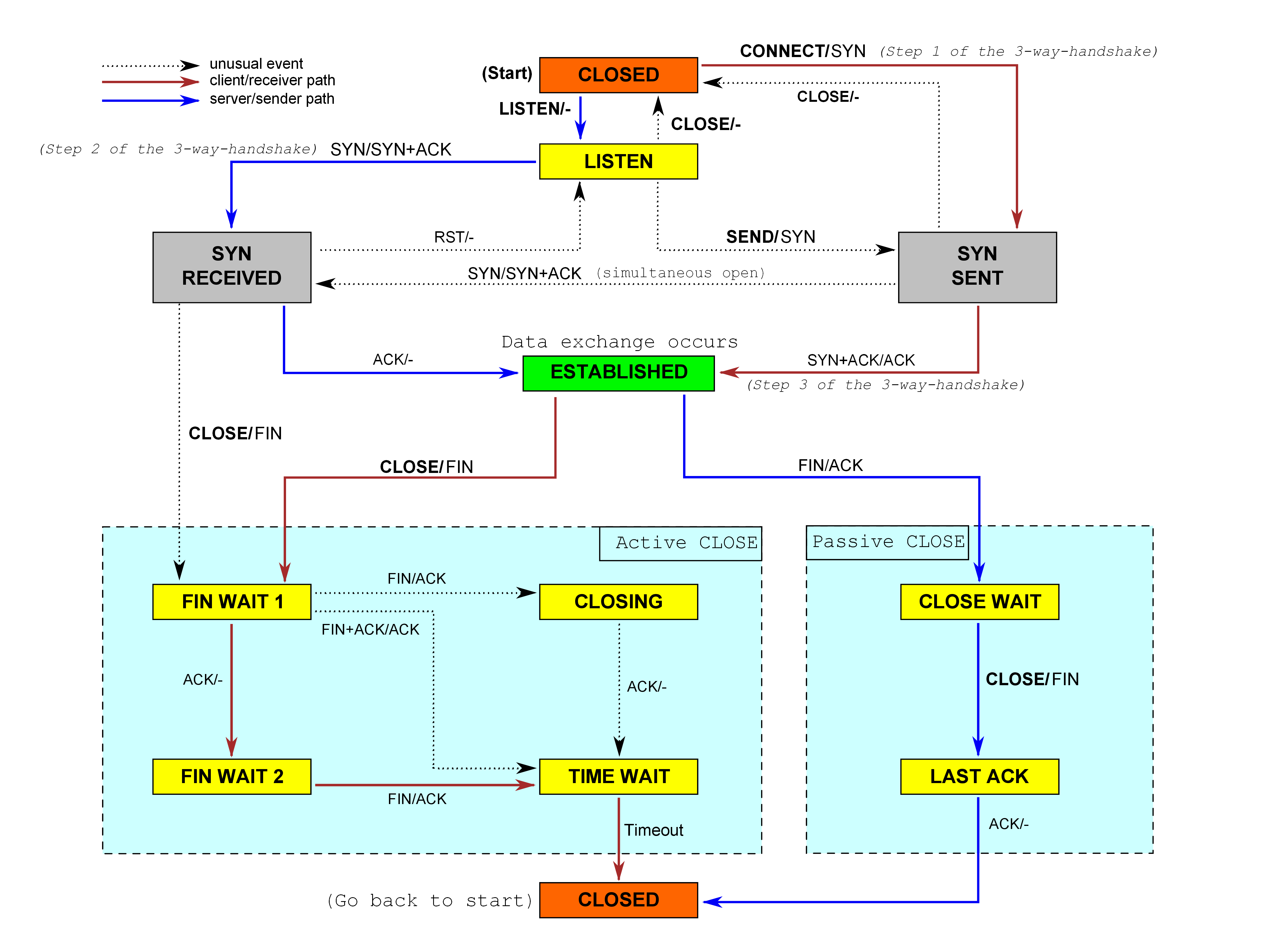
在顺利完成了上面几幅图中的状态转换之后,至少可以完成前面的55个测试。由于我没有完美通关本实验,因此不再贴出代码。
后记
Lab5和Lab6分别是关于链路层协议和路由转发的,对此兴趣不大,因此不再尝试,对计算机网络的学习就此告一段落。下一门打算在CMU 15-445/15-411两门课程中选择。