
SEIMI: Efficient and Secure SMAP-Enabled Intra-process Memory Isolation.” SEIMI uses the highly efficient SMAP for faster intra-process isolation. Its key contribution is actually securely running the user code in a privileged mode using virtualization techniques.
Abstract
SEIMI是一个高效的进程内内存隔离技术,用来保护进程的敏感数据。
SEIMI的核心是使用Supervisor-mode Access Prevention(SMAP),一种最初被用来防止kernel接触到用户空间的硬件特性,来实现进程内的地址隔离。
为了充分利用SMAP,SEIMI在特权模式下执行用户代码。除了使用新的基于SMAP的内存隔离设计,进一步开发了多种新技术来保证用户代码的安全性,例如使用描述符缓存来捕获潜在的段操作以及配置Virtual Machine Control Structure(VMCS)来使与控制寄存器相关联的操作无效。SEIMI优于现有的隔离机制,包括基于内存密钥保护MPK和基于内存保护扩展MPX两种模式。
特权模式下执行用户代码不会有问题吗:使用Intel VT-x技术,在VMX non-root模式下的ring 0级别执行用户代码,在VMX root模式下运行内核和其他的进程,并且将privileged data resources保存在VMX root模式下,在访问这些数据时触发VM eixts陷入到VM root模式,对于特权指令根据不同的分类使其无效化或抛出处理器异常并由SEIMI模块模拟这些指令的内容代为执行
Descriptor Cache: 为了更快的访问段内存,x86处理器在一个特殊的cache descriptor中保存了每个段描述符的副本。这样可以避免处理器在每次访问内存时都要访问GDT。每个段选择符(CS,SS,DS,ES,FS,GS)的cache包含了所有的GDT中能够找到的bit和字段,包括描述符类型,访问权限,基地址和limit。在保护模式下,无论何时有数据写入段选择符时这些字段GDT或LDT中的数据填充。在实模式下,处理器生成了内部的入口,因为没有在这种情况下没有GDT,并且在实模式下并不是所有的字段都会被填充。
1. INTRODUCTION
为了保存敏感数据,提出了information hiding(IH)来为敏感数据分配一块随机的地址,然后攻击者将无法知道地址因此也就无法读写敏感数据。
内存隔离可以分为基于地址的隔离和基于域的隔离。
基于地址的隔离检查不受信任的代码发起的每一次内存访问来确保其不能读取到敏感数据。这一方式的主要开销是由执行检查的代码带来的。最有效的基于地址的隔离是基于Intel Memory Protection Extensiions的MPX。在硬件支持下执行bound-checking.
基于域的隔离是将敏感数据保存在一块受保护的内存中。当受信任的代码访问这块内存时被授予访问权限,并在访问结束后撤销权限。
从不受信任的代码发起的内存访问并不能获取到访问权限,这一过程的主要开销来自于授予和撤销访问权限的操作。最有效的domain-based的隔离技术是使用Intel Memory Protection Keys(MPK)实现的。
现有的address-based和domain-based隔离相对于IH-Based隔离都会产生不小的性能开销。更糟糕的是当工作负载(即需要边界检查或权限转换的内存访问的频率增加)增加时,开销将会极大增加。
SEIMI充分利用了SMAP,用来防止kernel code访问用户空间的硬件机制。SEIMI以一种不同的方式使用了SMAP。SEIMI的主要的idea是在特权模式,即ring 0下运行用户代码,并且将敏感数据保存在用户空间中。SEIMI使用了SMAP来防止来自“privileged untrusted user code”来访问”user mode”的敏感数据。在受信任的代码(同时是在privileged mode)访问敏感数据时,SMAP被暂时disable,并在访问结束时重新enable。在SMAP enable时,任何对于用户空间的内存访问将会抛出处理器异常。因为SMAP被RFLAGS寄存器控制,而RFLAGS寄存器是线程私有的,disable SMAP仅仅在当前的线程内有效。因此,暂时关闭SMAP不会允许任何来自其他线程的并发的针对敏感数据的内存访问。
SEIMI中对SMAP的使用带来了新的设计问题:如何阻止ring 0 级别的用户代码破坏kernel和滥用需要特权的硬件资源。为了阻止内核污染,选择使用硬件辅助的虚拟化技术,例如Intel 的VT-x来以更高的权限运行内核,例如VMX root模式。用户代码运行在VMX non-root下的ring 0级别。因此,用户代码通过虚拟化就与内核进行隔离(所以是为了隔离内核对于敏感数据的访问?是这样的。)
related works: Dune 同样使用了Intel VT-x技术,来提供用户层面的代码。但是这需要代码运行在ring 0级别是安全的和可信的。 所以SEIMI的创新点在于,实现了代码在ring 0级别的安全和可信的运行?
为了支持不可信的代码运行在ring 0 级别,那么提出了多种新的技术来阻止用户代码滥用两种类型的硬件资源:(1)特权的数据结构:例如页表(2)特权指令
为了阻止用户代码访问特权数据结构,将所有的特权数据结构保存在VMX root模式下,而SEIMI 利用Intel的VT-x来强制所有的特权指令触发VM exit,即陷入到VMX root模式。之后SEIMI在VMX root模式下完成特权指令的执行,这样特权数据结构将永远不会暴露给用户代码。
为了阻止特权指令的执行,使用了自动和手动的方式来全面地判定这些指令并且使用SEIMI来使这些指令的执行无害化:(1)触发VM exits并且停止执行(也就是陷入到VM root模式后执行?)(2)使执行结果无效(3)抛出处理器异常并且停止执行。
使用SEIMI可能带来的好处:某些需要特权级别才能读的东西,可以无需上下文切换,而由user code直接读完。
SEIMI使用SMAP不会产生额外的开销吗?会产生额外的开销,但是相对于MPX和MPK来说,更加安全并且效率更高
这是在防止什么攻击?defense mechanism用来防御memory-corruption 攻击,但是这些mechanism需要一个隔离的内存空间来保存其部分敏感数据的安全,SEIMI的作用是为这些防御机制提供一定的隔离的空间,并且SEIMI的安全性与defense mechanism的安全性是可以相互保证的。
用户代码运行在VMX non-root模式下的ring0 级别,kernel运行在VMX root模式下,那么这与之前有什么区别?事实上,只有target process运行在VMX non-root模式下的ring 0级别,对于kernel和其他的进程都是运行在VMX root模式下。这样利用SMAP,target process将无法随意写U-page。
我的一个新的问题:隔离是指哪方面的隔离?因为隔离的内存区域有S-page和U-page,两个虚拟页表映射到同一块物理区域,同时ring 0级别还可以通过修改AC标识位来开启对U-page的写,在后面禁止POPFQ修改AC标志位,所以target process实际上也不能进行读写,应该是由kernel来决定能否进行读写的 实际上,应该是只允许trusted code在ring 0级别下通过STAC/CLAC两条特权指令开启/关闭SMAP,从而实现了特定的内存区域的隔离
contribution:
- 一个新的domain-based 隔离机制
- 隔离用户代码的新的技术。
- 来自实施和评估的新见解
Background
A. Information Hiding
通过随机地址实现,效率高。
B. Intra-process Memory Isolation
相对于information hiding,这种方法可以在保护敏感数据免受memory-corruption攻击方面提供更强的安全性保证。将敏感数据分成了三类:
- Confiedntiality only:授予受信任的代码读权限,并从不受信任的代码中撤销权限。在这些机制中,敏感数据是有效的的、随机目标的控制传输的目标地址。由于目标地址仅在加载时被写入,因此他们可以被存放在只读内存中。
- Integrity only:某些防御机制,例如CFI的shadow stack,允许敏感数据被受信任的代码读和写,但是只允许被不受信任的代码读。这种机制中,敏感数据包括了控制数据例如返回地址和函数指针,这需要在运行时被防御机制更新。只要完整性得到了保证,攻击者不能使控制流转向 ,因此读权限可以被授予攻击者。
- Both confiedntiality and integrity.敏感数据包含着一些秘密信息,例如需要运行时更新的代码地址。因此,不受信任的代码必须被阻止读和写敏感数据。
Existing memory-isolation mechanisms
address-based 模式通常将隔离的内存域放在高地址空间,所以内存访问可以只需要检查一个边界而不是两个边界。
Domain-based模式通过暂时关闭访问限制来保护敏感数据。当defense code想要访问敏感数据时,隔离机制暂时禁用访问限制,并在访问结束之后重新开启限制。处理器提供多种硬件支持来控制访问限制,包括MMU中的虚拟内存页限制,EPT和MPK中的物理内存页限制等。Intel MPK的效率最高。
特别是,对于只需要完整性保护的敏感数据,domain-based模式通常只需要控制写限制,因此可以在defense code 仅执行写指令时避免切换访问权限
C. Intel VT-x Extension
VT-x将CPU划分为两个操作模式:VMX root模式和VMX non-root模式,前者运行VMM,后者运行客户机OS。VM控制结构促进了VMX不同 模式之间的转换,硬件自动保存和恢复大部分架构状态。VMCS也包括了大量的配置参数,以允许VMM控制客户VM,这让VMM有足够的灵活性来决定将何种硬件暴露给客户机。例如,一个VMM可以配置VMCS来决定VMX non-root模式中的哪些指令和何种异常能够陷入VM root模式。同时,客户机还可以通过VMCALL指令来手动触发VM exit.
D. SMAP in Processors
为了防止内核无意中执行了用户空间的恶意代码,Intel和AMD提供了SMAP来禁止内核对于用户空间内存的访问。由于kernel需要直接和频繁地访问内存,因此启用和关闭SMAP是非常快的。
在x86中,运行时地状态被分成supervisor mode和user mode。当目前的特权级是3时,状态为S-mode,当特权级小于3时,状态是U-mode。同时,内存页被分成supervisor-mode页和user-mode页,划分依据是页表入口中的U/Sbit。当SMAP被启用时,S-mode的代码不能访问U-page.S-mode的代码可以通过设置RFLAGS的AC标志来启用或关闭对于U-page的访问,处理器提供了两个仅能在ring 0级别执行的特权指令STAC和CLAC来设置和取消标志位。另外,POPFQ指令在S-mode执行,AC标志位也可以被修改。
我又懵了:SMAP是在什么时候用的?SMAP是拿来解决什么问题的?SMAP是用来防止ring 0级别的target process随意写U-page
Smode的代码不能访问U-page,但是S-mode又可以通过修改标志位来访问这部分代码,那么S-mode的代码能不能访问U-page。
III. Overview
A. Threat Model
SEIMI与传统的memory-corruption 防御机制的威胁模型相似。SEIMI的目的是为防范memory-corruption攻击的安全机制提供所需的进程内的内存隔离。目标程序可以是server或本地的程序。假设目标程序可以具有memory-corruption漏洞,因此可以被攻击者获得随意读写的能力。同时假设程序的开发者是无害的,所以恶意软件不在考虑的范围之内。但是目标程序可能允许在一个包装环境中的本地执行,例如,攻击者可能诱导web 用户点击恶意链接,然后恶意脚本可以在浏览器中本地执行。
同时假设memory-corruption defense是安全的,也就是说,破坏SEIMI的隔离是破坏防御机制的先决条件。由于防御机制目的是阻止memory-corruption攻击,因此当SEIMI有效时,攻击者无法执行代码劫持攻击或代码重用攻击来恶意地启用或禁用SMAP。换句话说,memory-corruption defense 和 SEIMI的安全性是相互保证的。更进一步的假设是目标OS是安全的并且是可信任的。
攻击者能做什么?本地执行自己的恶意代码?攻击者能够诱导用户执行在本地环境中执行恶意代码,但是使用SMAP的target process本身不能是恶意的。target process可以具有memory-corruption,攻击者可以通过这个漏洞进行随意读写
B. High-Level Design
由于应用代码目标是在用户模式下执行的,所有现有的内存隔离技术仅仅在这种模式下利用了硬件支持,例如Intel的MPK和MPX。这篇论文中,将注意力放到了特权级别下的硬件特性——SMAP。由于SMAP的切换比MPK要快,因此猜测使用SMAP将会导致更好的性能。
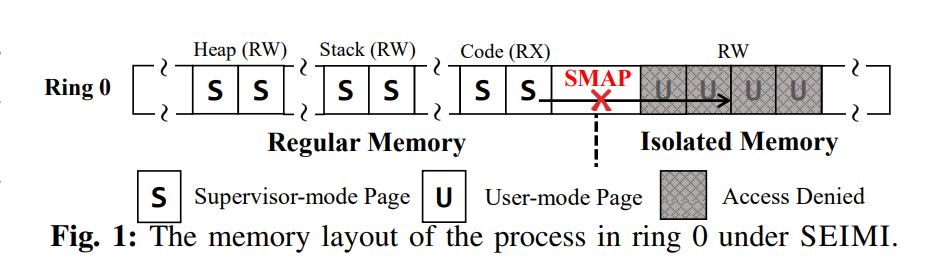
隔离的内存域分配在U-page中,其他的内存被分配到S-pages中。应用程序在ring0级别运行,因为STAC/CLAC指令仅仅能够在这一级别运行。SMAP是默认启用的。为了能够访问隔离的内存,受信任的代码使用STAC暂时禁用SMAP,当访问结束时,执行CLAC重新启用SMAP来阻止来自不受信任代码的内存访问。
虽然disable和re-enable之间存在时间窗口,但是不会影响安全性,因为SMAP是线程私有的,仅仅在当前线程内有效,而不会影响到其他的线程。
在ring 0级别运行不受信任的用户代码可能会影响内核的安全性,因此SEIMI借助于Intel VT-x技术将内核运行在ring -1级别, 即在VMX non-root模式下运行客户机,在VMX root模式下运行内核。
C. Key Challenge
在VMX non-root模式的ring 0级别运行用户代码可以实现基于SMAP的内存隔离而不会影响内核的安全性。
- C-1:区分SMAP读和写。在某些情况下,敏感数据可能只需要完整性保护,那么对于读操作的限制就会带来额外的性能开销。在某些其他情况下,又将会需要敏感数据可以被读而不能被写。因此需要区分读操作和写操作。
- C-2:阻止使用和操作特权数据结构。客户机VM需要管理其自己的内存、中断、异常、I/O等。某些数据结构如页表、中断描述符表IDT、段描述符表是特权级别才能被访问的。ring 0级别的攻击者可能泄露或修改这些数据结构以获得更高的权限。例如修改页表来使DEP失效。
- C-3:禁止滥用特权级别的硬件特性。
D. Approach Overview
Separating read/write in SMAP.为了解决C-1,基于共享内存方法提出了SMAP read/write separation技术,在为敏感数据分配隔离的内存域时,为同一块物理内存空间分配了两块虚拟内存,其中一块作为可以被同时读写的U-page,称为isolated U-page region,另一块被配置为只读的S-page,当受信任的代码需要修改敏感数据时,在关闭SMAP后操作隔离的U-page,当只需要读敏感数据时直接操作隔离的S-page。
Protecting privileged data structures.为了解决C-2,将privilegegd data structures和操作放到了VMX特权指令。也就是说这些指令只能够通过例如系统调用、异常、中断来通过内核来执行。
Preventing privileged instructions.特权级别下的硬件特性可以通过特权指令来使用。为了解决C-3,全面地收集了所有的特权指令,SEIMI让所有在VMX non-root模式下的特权指令无害化:(i)触发vm exits并停止执行.(ii)使执行结果无效(iii)抛出处理器异常并禁止指令执行。
为什么U-page可以被配置为可同时读写的,S-page要被配置为只读的?因为要实现读写分离。target process运行在VMX non-root模式的ring 0级别,SMAP不允许ring 0级别的代码直接写U-page,所以U-page要被配置为可以同时读写的,而ring 0级别的代码可以读写S-page,而要实现隔离一块内存区域的话就不能允许进程读写S-page,所以将其设置为只读。也就是说,S-page的只读靠R/W位来保证,U-page的可写靠SMAP的特性来保证,由此实现的读写分离。
IV. Security Executing User Code in ring 0
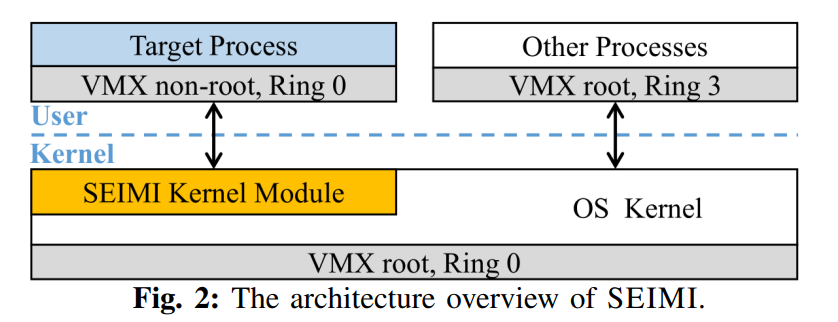
SEIMI的核心是管理VT-x的内核模块。在加载之后启用VT-x并且将内核放在VMX root模式中,使用SEIMI的进程在VMX non-root模式下运行在ring0级别,而其他的进程运行在ring 3级别。这一安排对内核透明,当系统从内核返回到target process时,SEIMI自动切换到VMX模式。
SEIMI模块包括三个关键的组件:内存管理、特权指令管理和事件重定向。内存管理组件用来为target process配置常规或隔离的内存以实现基于SMAP的隔离技术。特权指令管理组件用来阻止特权指令被攻击者滥用。事件重定向组件在进程通过系统调用、异常和中断访问内核时,配置和拦截VM exits。在拦截了这些事件之后,将请求传送给kernel进行真正的处理。这三个组件保证了用户代码在ring 0 级别的安全运行,并且实现了基于SMAP的内存隔离。
A. Memory Management
与传统的VM相比,SEIMI没有在VMX non-root模式下运行的OS来管理内存。因此SEIMI必须完成页表的管理,需要满足以下的要求:
- R1:宿主机管理来自客户机的系统调用,所以用户空间的内存布局应该在宿主机和客户机的页表中是相同的。(也就是说,需要在Host和guest中维护两份相同的页表,会影响效率?确实会影响效率。将host的0~255个页目录项拷贝到guest的页表中,并且将254和255两个虚拟页表映射到同一块内存区域来作为隔离区的内存。另外SEIMI监视对于host页表的更新,在更新时同时更新Host和guest两者的页表。)监视页表的具体过程
- R2:客户机的物理内存应该被宿主kernel直接管理
- R3:SEIMI应可以灵活的配置客户机虚拟内存空间中的U-page和S-page
- R4:客户机不能访问宿主机的内存
一种简单的实现方式是复制host用户空间的页表作为SEIMI模式的guest页表,guest 页表包括从guest虚拟地址到host物理地址的直接映射,并且将非隔离的用户空间的页改变为S-page。(host不是内核吗?为什么会有个页表?host维护一个VMX root模式下的页表,实际上也应该是整个操作系统的页表。SEIMI应该是个模块,guest作为一个虚拟机维护自己的页表)
因为guest 页表在host的kernel中被分配,并且kernel的内存在guest页表中是不可见的,所以guest的页表将不会暴露给攻击者。(前面说guest的页表是从host复制过去的?好像懂了,页表是保存在内核空间的,攻击者在用户空间无法读取到页表内容?似乎是的,在这个模型中,攻击者似乎只能在VMX root模式的ring3级别下运行,因此无法触及到真正的页表)
我好像又懂了,应该把这个东西作为虚拟机来理解,guest的内存实际上是从Host中分配出来的一个大文件,然后guest的页表是从host的物理空间映射过来的内存,而与host的页表无关
但是因为页表是树形结构,并且有X86_64有四个级别(PML4,PDPT,PD,PT),因此复制整个页表的开销过大。
A shadow mechanism for only page-table root.为了减少开销,提出了一种复用低三级页表的方式,这样只需要复制第一级页表。
PML4有512个条目,每个索引512GB的虚拟内存,所以全部的虚拟内存是256TB。其中前256条指向用户空间,后256条指向内核空间,分别是128TB.复制host页表的PML4页到一个新的页,称为PML4‘页。在新的页中清空了后256条索引,因为guest不应该访问到内核的页,然后前256条就拥有了和host相同的索引。
Configuring the U-page and S-page.每个页表项都有一个U/Sbit位来表明是用户模式还是supervisor-mode。一个虚拟内存页如果相关联的所有的页表项的U/S bit都是1,那么就是U-page,否则是S-page。在host page table中,所有的用户空间的页都是U-page,但是由于guest的页表是从host的页表中拷贝过来的,所以大部分页表项是完全相同的,(也就是说,拷贝完的时候guest的页都是U-page,因此要有一种方法把部分U-page转变为S-page)

采用如下策略配置S-page, PML4’ 的 0~254条页表项被修改为supervisor-mode,即只需要将U/S bit改为1,S-page被用来作为没有隔离的内存域,而第255个页表项依然是用户模式,保留作为隔离的内存域。这样SEIMI将在guest的页表中将non-isolated内存域变成了S-page,而host页表中对应的页还是U-page。
Supporting the read-only isolated S-page region.为了将相同的物理页映射为只读的S-page和可读可写的U-page,SEIMI首先保留了PML4‘的第254个页表项,并且让他指向与第255个页表项相同的PDPT页,之后SEIMI将第254个page设置supervisor-mode 页表项,同时反转页表项的R/W位来标记这个页是只读的。
(那么之前第254个页表项索引的地址应该放在哪?应该是只能被VMX root下的进程访问,而无法被VMX non-root下的进程访问)
B. Intercepting Privileged Instructions
拦截特权指令一共三步?
- 识别特权指令:识别有两步,第一步是自动分离特权指令,第二步是手动验证。目标是找到具有特权或在ring 0和ring3级别运行时具有不同功能的指令。首先为测试程序的每条指令都插入随机的操作数并在ring 3级别下运行。通过自动捕获保护异常和无效的操作码异常来自动的获取到所有的异常。之后手动查阅Intel的开发手册来确定第一部的所有的指令都是特权指令,同时还找出了在ring 0和ring 3级别下功能不同的指令。Intel VT-x提供了监视特权指令执行的支持,SEIMI利用这一支持来破坏指令正确执行所需的执行条件。如果有多条执行条件,那么选择一条开销最小的进行破坏。
- 触发VM Exit:当EXIT-Type的指令在VMX non-root模式下执行时,触发VM exit事件并且被VMM捕获。VM exits被分为无条件退出和有条件退出。有条件退出指的是VM exits依赖于VMCS中控制字段的配置。为了阻止这些指令在ring 0执行,SEIMI显式的配置了EXIT-Type的特权指令来触发VM exits.
- 抛出异常:对于EXP-Type指令,SEIMI在执行过程中抛出异常。
- 抛出#UD。对于20行的指令,取消了VMCS中对这些指令的支持,所以在执行时将会抛出无效的操作码异常。
- 抛出#GP。在16~18行的指令,Intel VT-x没有提供任何拦截的支持。这些指令与段操作有关,并且这些指令改变了段寄存器,因为应用在ring 0级别运行,所以攻击者可以切换到任意的段,因此同样需要控制这些指令的执行。观察到在改变段寄存器时,硬件将会使用target selector来访问段描述符表。在这个过程中,如果段描述符表是空的,那么CPU将会抛出一个general protection exception(#GP)。因此可以利用这个特性来清空描述符表。但是这会导致两个问题:
- 在描述符表被清空时,如何确保程序的正常执行。(段描述符表用于每一条指令的寻址)2.在描述符表是空的时,如何确保与段相关的指令的正常功能。
- 使用描述符缓存的段切换异常:为了解决这两个问题,使用了X86中的段描述符缓存。
- 每个段寄存器有两个部分,一个是可见的部分,用来保存段描述符,一个是不可见的部分,用来保存段描述符的信息,隐藏的部分同时被叫做描述符缓存。在执行不切换段的指令时,硬件直接从描述符缓存中读取段描述符的信息。只有当切换段的指令执行时,硬件才会访问段描述符表并且加载目标端的信息到描述符缓存。由于X86允许描述符cache与描述符表不一致,因此可以在cache中填入正确的段描述符信息,并且清空段描述符表。
- 具体地说,设置了VMCS guest状态的所有字段的段寄存器的内容,包括选择器和相关联的段描述符的信息。当进入VMX non-root状态时,信息将会被直接加载到guest的段寄存器,然后设置GDTR和LDTR的base和limit字段为0。这样不会影响到不切换段的指令的执行,而只会在切换段的指令执行时抛出异常。
- 所以说,cache是Hidden Part,在不切换段时,硬件直接从cache中读取出来段的信息,而切换段时,才会访问段描述符表,并且把target segment information加载到cache中。 做法是在cache中保存正确的段信息,然后把描述符表清空掉 具体地讲,设置了VMCS的guest-state字段和相关联的段描述符的信息。把描述符表清空掉之后,再切换段时需要通过段选择器访问段描述符表,进而抛出异常
- 当SEIMI捕获到抛出的异常时,SEIMI模块检测这些操作是不是合法的,如果合法,那么模块将会模拟这条指令,把被请求的段信息填充到VMCS中与之相关的段寄存器中,并且返回到VMX non-root模式。合法指的是程序在ring 3级别下访问
- 抛出#PF。SYSEXIT/SYSRET指令将切换段并且将固定的值填入到描述符缓存中,而不需要访问段描述符表。因此这两条指令将不会抛出#GP异常。但是因为这两条指令的执行将会把CPL设置为3,并因此而在ring 3级别下执行,这就因此保证了这些指令在ring 3下不会访问到任何S-page。所以在CPU执行到SYSEXIT/SYSRET的下一条指令时,将会抛出一个page fault异常。
- 为什么?只有ring 0 级别能够访问S-page?对的,只有ring 0级别可以访问S-page,由于指令应该是从S-page来读取的,并且在SYSEXIT/SYSRET执行后变成了ring 3级别,因此在取下一条指令时会抛出#PF异常。SYSEXIT/SYSRET指令有什么具体的功能?
- 使执行无效:对于INV-Type类型的指令,直接使执行结果无效,从而不会允许这些指令修改任何内核状态或获取信息。
- 与CR*寄存器相关的指令。对于%CR0到%CR4的控制寄存器相关的load/store指令,Intel VT-x支持了VMCS配置来控制这些指令的操作,两个寄存器有一套guest/host的掩码和read shadows.guest/host mask的每个bit指明了寄存器的所有权,如果对应的bit是0,那么guest可以读和写,否则,host可以读和写。在后一种情况中,当guest读寄存器的值时,将会从read shadows中读取,而在写寄存器的值时,将不会真的写入对应的寄存器。
- 基于上面所说的特性,SEIMI将guest/host掩码的所有的bit设置为1(这样guest将无法修改CR0和CR4寄存器),将read shadows的所有的bit设置为0,也就是说guest读取的CR0和CR4寄存器的值为全0,写的话没有任何影响。
- %CR2控制寄存器在出现page fault时用来保存错误的地址,因为guest的异常直接触发了VM exits,错误的地址将被保存在VMCS中而%CR2并没有记录任何错误的地址,所以攻击者将不会从这个寄存器中读取到任何有用的信息,因此读取这个寄存器是没有意义的。
- SWAPGS, L[AR/SL],VER[R/W]。SWAPGS指令被用来快速交换%GS和MSR中的地址,SEIMI将MSR寄存器与%GS段基地址设置为相同的值,所以SWAPGS这条指令没有任何意义。LAR和LSL指令被用来获取访问权限和从关联的寄存器获取限制信息,VERR和VERW用来验证一个段时可读的和可写的。 因为描述符表已经被清空了,所以执行这条指令将会触发一个描述符加载段冲突和RFLAG。ZF标识位将会被设置为0.SEIMI无法模拟这些指令的执行,所以这些执行将会被忽略。幸运的是,这四条指令在应用程序中很少会被用到。
- 所以不会有任何指令会使这两个寄存器的值不一样吗?
- CLI/STI和POPF/POPFQ。CLI/STI指令可以修改系统标记IF,记录在RFLAGS,POPF/POPFQ指令可以修改IOPL和AC。IF标志位用来屏蔽硬件中断,IOPL用来控制I/O相关指令的条件执行。在SEIMI中,对于IF和IOPL修改将没有任何的作用。中断和I/O指令都会触发无条件的VM exits。
- 为什么修改不会产生任何作用?因为privileged hardware resources都被放到了VMX root模式,因此在中断或I/O时会触发VM exits陷入到VMX root 模式,由内核来处理
- 消除POPFQ对AC的影响。 POPFQ指令可以通过修改AC标志位启用或关闭SMAP。因此,需要确保用户代码无法使用POPFQ指令或修改AC标志位。但是由于POPFQ需要被执行,因此选择阻止其修改AC标志位。在每一条POPFQ指令前插入一条and指令,所以stack对象的AC标志位永远是0,也就是说永远无法通过POPFQ指令将AC标志位修改为1。因为在威胁模型中,攻击者无法劫持控制流,因此无法跳过and指令。
- 这是怎么做到的在POPFQ前插入一条指令?我也不知道
- 为什么这里要避免用户指令启用或关闭SMAP?应该由谁来启用SMAP?应该是内核/SEIMI来决定能不能进行读写的,否则使用SMAP毫无意义
C. Redirecting and Delivering Kernel Handlers
System-call handling.SYSCALL指令无法将控制流从VMX non-root转换到VMX root模式。使用VMCALL来替换SYSCALL,VMCALL通过将代码页映射到目标内存空间,包括两条指令VMCALL和JMP *%RCX。之后设置guest的IA32_LSTAR MSR寄存器,这一寄存器用来指明系统调用的入口,将其值改为VMCALL的地址。
- 一旦进程执行了SYSCALL,控制流将会被转移到执行VMCALL来触发hypercall,并且 SYSCALL的下一条指令的地址将会被存放到%RCX寄存器中,SEIMI模块向量通过内核系统调用表hypercall,并且调用关联的系统调用句柄。在其执行返回后,模块执行VMRESUME来返回到VMX non-root模式,并且执行JMP指令跳转到SYSCALL的下一条指令。
Hardening system calls against confused deputy.攻击可以利用系统调用来间接的访问被隔离的内存区域,因为OS内核拥有特权访问整个用户空间,并且他们的代码没有被address-based和domain-based方法限制。SEIMI动态地检查指定的地址和count参数来确保指定的内存范围与隔离的内存区域没有重叠地区域,否则,SEIMI将会在系统调用中返回一个error.主要针对write/read这种通过内核来执行的I/O函数等。
Interrupts and exceptions handling.在SEIMI中执行目标进程期间,所有的中断和异常都会触发VM exits,并且这些VM exits应该被SEIMI处理。SEIMI配置了VMCS,所以当中断或异常产生时,控制流将会转移到SEIMI模块,SEIMI通过中断描述符表处理中断或异常,执行权限检查,并且调用对应的处理函数。因为target process 在ring 0 级别运行,error_code的U/S bit为0,为了确保内核的异常处理函数可以正确处理异常,因此将U/Sbit设置为1。在处理函数返回之后,模块执行VMRESUME返回到VMX non-root模式,
- 隔离S-page区的缺页异常的故障地址要重定位到隔离的U-page区,因为host页表的隔离S-page区没有映射,内核不能处理该区域的异常。 我的理解:第254个页表项被配置为S-page,第255个页表项被配置为U-page,作为隔离存储区,其中两个页表都是映射到原来host页表的第255个页表项对应的内存区域,0~254个页表配置为S-page,其中第254个是只读的,第255个配置为U-page,其实只要把0~254个顶级页表目录项的U/Sbit置为0,就变成了S-page
- 直接设置U/Sbit不会出现问题?不会,S-page的只读由操作系统的R/W标志位确定,U-page的读写由SMAP机制来保证
Linux signal handling:SEIMI在控制流从VMX root模式下转换到VMX non-root模式下时处理信号。模块在返回到VMX non-root模式之前,通过执行signal_pending()函数检查信号队列,队列中存在信号,那么模块调用do_signal()函数来保存中断上下文,并且切换到信号处理上下文,之后将新的上下文设置为VCPU,并且返回到VMX non-root模式来执行处理函数,当处理器返回时,通过sigreturn()陷入到SEIMI模块。模块将之前保存的上下文恢复到VCPU,然后返回到VMX non-root模式继续执行。
V. Implementation
A. SEIMI APIs和用法
如果参数need_ro是false,那么sa_alloc()将会只分配隔离的U-page,并且返回基地址。如果need_ro是true,那么会同时分配一个S-page,与U-page共享内存。S-page的偏移值将会通过参数offset返回,假设U-page的及地址是addr,那么S-page的基地址是addr+offset。因此即使SMAP启用之后,defense依然可以通过addr+offset访问S-page。
为了在VMX non-root模式下运行目标应用,用户应该加载SEIMI的内核模块并且在运行前指定target application。当内核模块加载完成后,为所有的核心启用VT-x并且立即将当前的系统放在VMX root模式下。
B. The Start and Exit of the Target Process
SEIMI首先调用内核中的初始处理函数来初始化进程,然后为target process创建VCPU结构并且使用target process 的上下文初始化VCPU。在进程在VMX non-root模式下的ring0级别运行时,VCPU包括了初始的上下文,RIP寄存器保存了进程的入口,段选择器CS和SS的RPL字段被设置为0。之后SEIMI使用VMLAUNCH指令来将进程放到VMX non-root模式的ring 0权限下执行。因为%CS的RPL域是0,因此目标进程将进入ring 0级别执行。
对于子线程或子进程,同样会为进程/线程创建一个VCPU并将其放入ring 0级别下运行。
段选择器CS SS ES DS保存了段地址。
SEIMI为每个子线程都创建了一个新的VCPU,并且线程通过设置RFLAGS中的AC标志位仅在当前线程内有效,而不会影响到其他线程,因此SEIMI是线程安全的。
线程独立特性确保了即使在SMAP禁用的情况下发生VM exit事件,依然能够保证安全性。
同时AC标志位默认置0,即SMAP默认是启用的。
C. 实现安全的内存管理
避免PML4’中的第254和第255号的重叠
为了避免应用使用隔离的内存区域,SEIMI模块通过拦截内核中的load_elf_binary函数并修改这个进程的mmap_base来防止堆栈和ld.so被分配到这个区域。由于用户可能使用mmap()函数在固定的地址分配一块内存空间,因此SEIMI同样验证这个函数来避免在隔离的内存区域分配内存。
处理VSYSCALL
由于部分系统调用会被放在内存中的固定地址并且超出了用户空间的范围,因此需要PML4’的第511个页表项,所以需要设置PML4‘511个页表项所指的页目录项。这个页被设置为S-page.
第511个页目录项不能被全部复制过来
跟踪PML4页面的更新
SEIMI将PML4页面设置为只读的,所有的写操作将会触发缺页中断,然后被SEIMI拦截,这可以通过配置中断描述符表 IDT 来实现。SEIMI模拟写指令的执行并且同步到了PML4’上。由于PML4是顶级页表很少被 修改,因此这只会有非常小的性能损耗。
避免利用TLB访问内核
使用Virtual Processor Identifier(VPID)来避免频繁进行TLB刷新带来的性能开销。通过为每个客户VM和host配置一个唯一的VPID,并且仅仅可以通过VPID分组来访问自己的TLB表项。
为了让guest TLB与页表同步,SEIMI同样通过使用mmu_notifier机制拦截了页表更新操作,并且使target process相关联的TLB表象的映射无效。
VPID是Intel 提供的机制
这是怎么添加的VPID,并且怎么实现的分组,TLB应该是硬件实现的
VPID是在硬件上对TLB资源管理的而优化,通过在硬件上为每个TLB项增加一个标识,用于不同的虚拟处理器的地址空间,从而区分Hypervisor和不同处理器的TLB。硬件区分不同的TLB项分别属于不同的虚拟处理器,因此可以避免每次进行VM-Entry和VM-Exit时都让TLB全部失效,可以提高VM切换的效率。所以说,TLB在VM状态切换后,不会全部切换?因此可以减少一些不必要的页表访问,减少了内存的访问次数,提高Hypervisor和客户机的运行速度。
处理API请求
在sa_alloc(),SEIMI将会调用do_mmap(),没太看懂
VI. Evaluation
使用了四个防御机制:OCFI SS CPI AG(都是IH-based defense)
在四种情况下执行实验:1, 仅被IH-based保护 2, 被MPX-based保护 3. 被MPK-based保护 4.被SEIMI-based保护
前面不是说只使用IH-based defenses吗,回过头来仔细看看
VM exits的开销更高。
测试了四个基于IH的防御机制,使用SEIMI来保存秘密数据。
Microbenchmarks:使用lmbench来测试负载。为了避免与domai-switching 的负载混淆,直接在SEIMI上面运行lmbench来检测内核指令的负载。
Macrobenchmarks:使用上面的四个IH防御机制来保护每个benchmark。测试了四种情况:分别被IH、MPX、MPK、SEIMI保护。 baseline是无任何保护措施。采用IH、MPX、MPK、SEIMI分别保护基准程序,比较其性能
Real-world applications:选择了12个常用的服务器或桌面程序。
Microbenchmarks Evaluation
SEIMI在处理轻量级的系统调用和信号时,引起的开销更加严重。轻量级的系统调用测试主要用来测试从用户空间陷入到内核态的开销。相比之下,hypercall的开销比system call更高。结果就是,内核操作非常简单的系统调用在启用SEIMI后有更重的开销负载。对于信号处理,SEIMI在保存和恢复中断上下文上需要执行额外的指令操作。
上下文切换时间定义为保存一个进程状态到恢复另一个进程状态的时间。进程数相同时,工作集更大时SEIMI的负载更小。为什么? 工作集更大,不会频繁换页引起从VMX non-root模式陷入到VMX root模式,因而开销更小
性能分析:SEIMI的性能负载比MPX-based和MPK-based两种模式更小。但是在某些情况下,MPX-based比SEIMI更优。原因解释:address-based模式的负载主要来自于边界检查,而domain-based的负载主要来自于开启和取消权限。因此,哪种方式更好取决于保护的负载。定义CFreq为每毫秒边界检查的次数,而SFreq为每毫秒权限切换的次数。实验结果表明,在边界检查的频率是进程切换频率的52倍时,SEIMI优于MPX。
随着权限切换频率的增长,SEIMI相对于MPK的性能优势更加明显,SEIMI的优势主要是由使用STAC/CLAC的SMAP切换比使用WRPKRU的MPK更加迅速。因此对于MPX来说,SEIMI比MPK拥有更大的性能优势。
Discussion
Overloading the AC flag
RFLAGS寄存器中的AC标志位在U-mode下被使用时是用来进行内存对齐检查的,在S-mode下被使用时被复用为控制SMAP。因此SEIMI无法依靠AC标志位实现对齐检查。事实上,SEIMI应该就是在S-mode下使用的AC标志位,并使用其控制SMAP。SEIMI使用STAC/CLAC来启用和关闭SMAP。
Nested virtualization
SEIMI使用VT-x技术,所以除非目标hypervisor支持嵌套虚拟化,否则不允许SEIMI在虚拟机中使用。
进行了两个测试:(1)在SEIMI上运行SPEC,在KVM上运行SEIMI
(2)在SEIMI+KVM上运行lmbench
Possible incompatibility with future instructions.
如果处理器支持了新的指令,依然可以通过相似的方法拦截部分指令的执行。
Transient execution attacks
address-based和domain-based防御机制都容易遭受Meltdown-type攻击。
Related Work
Leveraging privileged hardware for user code.
Dune在VMX non-root模式的ring 0级别运行用户进程,允许进程管理异常、页表和描述符表等。因此需要进程本身是安全地和可信的。对于不受信任的代码,Dune在ring 0级别运行一个沙盒,并在沙盒中以ring 3级别运行进程。
SEIMI相对于Dune的本质不同在于,SEIMI允许不受信任的代码在ring 0级别运行,以牺牲安全性的代价换取了技能的提升。同时采取了其他方式来保证安全性。因为在ring 3级别运行代码会产生频繁的上下文切换,从而带来巨大的开销
SEIMI的一些原创设计:使用SMAP实现进程内高效的内存隔离,设计了新的内存虚拟化方式将guest的虚拟地址直接转换为host的物理地址,因此避免由TLB不命中带来的内存虚拟化开销。传统的地址转换方式:guest的虚拟地址通过guest的页表转换为guest的物理地址,然后guest的物理地址通过EPT(扩展页表)转换为host的物理地址
【57】证明SMAP可以被绕过
几个问题
- SEIMI解决的问题是什么
- 现有的防御memory-corruption攻击的技术都需要进程内的敏感数据的机密性和完整性保护
- 现有的能够保护进程内敏感数据的技术:information hiding,address-based isolation(代表是Intel的MPX),domain-based isolation(代表是Intel的MPK),information hiding的安全性不足,MPK和MPX的效率较低
- SEIMI基于SMAP,实现了相对于现有的intra-process隔离技术更加高效的进程内的内存隔离技术,
- SEIMI是怎么解决这个问题的
- 借助于Intel VT-x技术,将target process放在VMX non-root的ring 0级别运行,将内核和SEIMI放在VMX root模式的ring0级别运行,其他的进程都放在VMX root模式的ring 3级别来运行。
- 利用SMAP实现部分内存的隔离,即ring 0级别的进程无法随意读取U-page,将target process的页表分成两种,其中0~253页表设置为S-page,正常使用,第254个目录项设置为只读的S-page,第255个目录项设置为U-page,可读可写,由于SMAP的限制,ring 0级别下运行的target process无法直接写U-page,需要通过STAC/CLAC来开启读的权限。同时第255个目录项和第254个目录项两个不同的虚拟页目录项映射到一个共同的地址空间,区别只在于R/Wbit不同和U/Sbit不同。同时,第0~255个页表项由kernel的顶级页表复制而来,并且SEIMI将内核的所有U-page设置为只读的,因此在内核希望修改PML4的页目录项时会触发缺页中断,SEIMI处理这个中断,模拟该指令的执行,同步修改host页表和guest页表。而guest无法修改自己的页表,页表属于privileged data structures,由SEIMI负责管理,在guest希望修改页表时应该抛出异常然后由SEIMI交给kernel来处理,所以guest在希望修改自己的页表时会触发VM exits,由在VMX root模式下运行的kernel来完成。实际上应该是trusted code完成对于SMAP的关闭和重新开启,而untrusted code应当只允许读而不允许写隔离区域。
- 同时SEIMI会根据指令执行的条件和结果,阻止特权指令的执行或使指令的执行无效化。
- 问题来了,U-page是可以被trusted code访问而不能被untrusted code访问还是均不能被访问(即在访问之前需要经过SEIMI鉴权)?应该是只有trusted code可以使用STAC/CLAC来启用和关闭SMAP,因此只有trusted code可以写U-page,而untrusted-code只能读隔离区
- 那么SEIMI做了什么呢?SEIMI的工作主要分成三个部分:
- 内存管理
- 拦截特权指令:
- SEIMI拦截ring 0级别的所有的特权指令并且阻止其访问privileged hardware features。
- 大部分特权指令可以通过Intel VT-x技术监视其执行,SEIMI可以利用这个来拦截,其他的指令SEIMI通过使其执行条件无效化来实现。
- 当EXIT-Type类型的指令在VMX non-root模式下执行时,可以触发VM exit。
- 抛出异常。对于EXP-Type类型的指令,SEIMI在执行时抛出异常。
- 取消VMCS的支持
- 涉及到切换段的指令,将段的信息保存在VMCS的guest-state字段中,清空段描述符表,在段描述符cache中保存正确的信息,这样可以保证不切换段的指令正常执行,切换段的指令抛出异常。
- 使指令的执行结果无效化。对于SWAP,使两个寄存器的值始终保持一直。对于POFPQ,在前面加一条and,使其无法通过POPFQ指令修改AC寄存器。对于CR*寄存器相关,将guest/host mask全置1,将read shadow置0.
- 重定向和交付给内核处理函数:
- 对于系统调用的处理,SEIMI将代码页映射到syscall的目的地址,相当于执行VMCALL和JMP %RCX指令,将SYSCALL的下一条指令的地址存在RCX寄存器中。SEIMI通过内核的系统调用表来调用相关的系统调用函数,并在处理函数返回后调用VMRESUME指令来返回到VMX non-root模式并执行JMP指令来返回到控制流中。
- 增强系统调用的抗代理人攻击的特性。因为内核可以访问整个用户空间,并且不会被地址检查和域检查限制,因此可以通过 read/write等系统调用来读取到不应该被访问的系统调用。SEIMI动态的检查这些系统调用访问的地址范围与隔离的内存区域是否有重叠。如果出现重叠,SEIMI返回错误,否则正常执行系统调用。
- 中断和异常处理。target process的中断和异常应该被SEIMI处理,所以SEIMI通过配置VMCS,使得在中断或异常触发时,控制流将会转移到SEIMI模块中。之后通过中断描述符表执行权限检查,并调用对应的处理函数。同时对于只读的S-page的访问将会被重定位到U-page中。在处理返回后,调用VMRESUME返回到non-root模式。
- Linux信号处理。在从VMX root模式返回到non-root模式时,模块检查信号队列中是否有未处理的信号。如果有未处理的信号,那么保存中断上下文,创建一个VCPU结构,并使用信号处理函数的上下文初始化VCPU,切换到VCPU,返回到non-root模式下执行完信号处理函数。处理完之后陷入到SEIMI模块中并恢复之前保存的上下文到VCPU,并返回VMX non-root模式下继续运行。
还有什么问题等待被解决
SIMP可以被绕过,这是否说明SEIMI其实还是有潜在的安全风险
- U-page和S-page的具体区别,能不能讲清楚
- 在表示上,应该是U-page的四级页表项的U/Sbit均为1,那么为U-page,否则如果其中任意一个页表项的S-page的U/Sbit为0,那么为S-page.
- 具体到功能上,S-page是在supervisor模式下的页面,而U-page是在user模式下的页面,由于SMAP机制的保护,ring 0级别下的code无法直接访问U-page,因此可以利用这个feature来实现页面的隔离。
- 在什么情况下应该使用哪种page
- 对于VMX root模式下运行的kernel和进程,其page保持正常
- 对于VMX non-root模式下运行的target process,其0~253 为S-page,与kernel的0~253个U-page相对应,因为ring 0级别,所以将其转换为S-page。
- 第254个entry和第255个entry用于实现读写分离,第254个page是只读S-page,第255个page是U-page,用于实现对于untrusted code的内存隔离
- SEIMI的执行流程
SEIMI首先调用内核中的初始处理函数来初始化进程,然后为target process创建VCPU结构并且使用target process 的上下文初始化VCPU。在进程在VMX non-root模式下的ring0级别运行时,VCPU包括了初始的上下文,RIP寄存器保存了进程的入口,段选择器CS和SS的RPL字段被设置为0。之后SEIMI使用VMLAUNCH指令来将进程放到VMX non-root模式的ring 0权限下执行。因为%CS的RPL域是0,因此目标进程将进入ring 0级别执行。
对于子线程或子进程,同样会为进程/线程创建一个VCPU并将其放入ring 0级别下运行。
段选择器CS SS ES DS保存了段地址。
SEIMI为每个子线程都创建了一个新的VCPU,并且线程通过设置RFLAGS中的AC标志位仅在当前线程内有效,而不会影响到其他线程,因此SEIMI是线程安全的。
线程独立特性确保了即使在SMAP禁用的情况下发生VM exit事件,依然能够保证安全性。
一共四级页表,把用户空间的顶级页表拷贝过来之后,那么对应的其余三级页表怎么办?可以直接使用吗
SEIMI是复用了其余的三级页表,只对顶级页表的0~255个页表项的U/S bit和R/W bit进行了修改,实际上映射guest还是与kernel映射到相同的物理内存上。
- target process和application process之间的区别?内核是怎么区分这两类进程的?
- target process运行在VMX non-root mode的ring 0级别,application process运行在VMX root mode的ring 3级别。
- 等下看看evaluation部分,target process到底包含哪些部分?
- 按我的理解,target process中可以有trusted process和untrusted process,其中隔离区域可以用来保存defense mechanism的敏感数据,然后使用defense mechanism来保护其他进程。
- target programs可以是服务器程序或本地程序,要求tartget programs可以有memory-corruption 漏洞,攻击者可以利用此漏洞拥有随机的读和写的能力。
- 内核怎么启动的,SEIMI是怎么加载的
- SEIMI编译target code,并且将其连接到SEIMI库的可执行文件,然后用户加载SEIMI的内核模块,并在运行SEIMI前选择target application。
- 在内核模块加载完毕后,为所有的核心启动VT-x,并且把现在的系统立即放在VMX root模式下运行。
- 用户应用通过execve()启动应用,对于other processes,在VMX root的ring 3模式下运行
- 对于target process的启动,调用初始的系统调用来创建进程,然后创建一个VCPU结构,使用target process的上下文来初始化这个VCPU。之后执行VMLAUNCH指令来将target process放入到VMX non-root模式下执行,由于%CS寄存器的RPL字段是0,所以会在ring 0级别下运行。
- 有哪些challenge,这些challenge是如何解决的
- 读写分离:U-page和S-page
- 阻止privileged data structures的泄露或修改:放在VMX root模式下
- 阻止privileged hardware features的滥用:收集所有的指令使其失效
- 如何进行内存管理的
- 因为host的kernel需要处理来自于guest的系统调用,因此host的页表和guest的页表应该保持一致
- guest的物理内存应该被host的kernel直接管理。(与传统的虚拟机相比,传统的虚拟机中,guest应该通过guest 的页表将虚拟地址映射为guest的物理地址,然后经过EPT扩展页表将guest的物理地址映射为host的物理地址。)而在SEIMI中guest和host共享页表,因此可以直接经过页表映射为Host的物理地址。
- SEIMI是复用了其余的三级页表,只对顶级页表的0~255个页表项的U/S bit和R/W bit进行了修改,实际上映射guest还是与kernel映射到相同的物理内存上。
- SEIMI可以用来保护什么
- 用来保护defense mechanism的敏感数据
- 其中包括critical data structures that are frequently checked against or used for protection
- 比如O-CFI的BLT,CCFIR的safe SpringBoard,Shuffler的code-pointer table等
- SEIMI在信号处理时会发生什么
- 再从VMX root模式返回到VMX non-root模式之前,SEIMI模块调用signal_pending()函数来判断队列中是否有信号
- 如果有信号存在,模块调用do_signal()保存中断上下文并且切换到信号处理上下文
- 将新的上下文加载到VCPU,返回到VMX non-root模块完成处理函数的执行。
- 在处理函数执行完后,陷入SEIMI模块,恢复之前保存的上下文到VCPU,之后返回到VMX non-root模块并继续。
- MPX MPK和SEIMI的区别是什么
- MPX是address-based
- MPK是domain-based
- SEIMI是基于SMAP,MPK和MPX都是利用的user space 的 硬件特性,而SEIMI是第一个基于ring 0级别的硬件特性的内存隔离机制。
- SMAP是Intel/AMD处理器支持的一种硬件特性。
- SEIMI如何切换不同的状态,切换时要做什么,开销有多大,需要考虑什么
- 在ring 0级别的进程触发VM exits时,切换不同状态:
- 访问特权数据结构:如页表等时触发VM exits陷入到VMX root模式,由SEIMI管理
- 执行特权指令:
- 部分特权指令触发VM exits并停止指令的执行,因此会切换状态。
- trusted code使用STAC/CLAC启用或关闭SMAP,以写隔离区的内存
- 使用SEIMI的进程在VMX non-root模式的ring 0级别运行
- 只有在SMAP关闭后S-mode的进程才能够访问U-page。
- 处理器提供了两种仅在ring 0级别下执行的特权指令STAC和CLAC来启用/关闭SMAP。
- 在ring 0级别的进程触发VM exits时,切换不同状态:
- U-mode和S-mode两个模式的区别,什么情况下应该使用哪种模式
- U-mode是用户模式,S-mode是supervisor模式
- ring 0时使用的是U-mode,
RFLAGS中的AC标志位的作用
AC标识位的作用是标识是否开启SMAP
Dune允许用户级别的线程在VMX non-root模式ring 0级别运行,同时允许进程管理异常、描述符表和页表。那么SEIMI在non-root模式下运行有什么特点?
SEIMI不允许进程管理异常、描述符表和页表,而是在VMX root模式下进行管理,不将这些特权数据结构暴露给进程
SEIMI的创新点?具体讲讲?
- SEIMI第一次使用处理器支持的硬件特性,即SMAP实现内存区域的隔离
- SEIMI使用了VT-x技术,将target process运行在VMX non-root模式的ring 0级别,并且将特权级别的数据结构保存在VMX root模式下,使用SEIMI拦截特权指令,实现了进程在ring 0级别的安全运行。这样避免了Dune中需要进程安全可信才能运行在ring 0级别的缺陷。
- SEIMI使VMX root和non-root模式复用三级页表,可以通过页表直接将guest的虚拟地址映射到host的物理地址中,而不需要通过guest的虚拟页表映射到物理地址,再通过EPT映射到host 的物理地址,减少了内存访问的开销。
- MPK/MPX可以执行代理人攻击,因为OS内核可以访问全部的用户空间,并且内核不会被address-bsed和domain-based限制,因此攻击者可以通过系统调用(read、write)来访问隔离的内存。为了解决代理人攻击,SEIMI动态检查指定的地址和count,以确保特定的地址范围与隔离的区域没有重合。否则,SEIMI返回error。
SEIMI,防御机制、通常的应用程序三者之间的关系?
- target process运行在VMX non-root模式下的ring 0级别,由SEIMI保护,防御机制应该是target process的一种,使用防御机制保护一些需要安全性的进程
- 内核运行在VMX root模式下的ring 0级别,其他的进程,即other process运行在VMX root模式的ring 3 级别
untrusted code和trusted code访问U-page的不同操作?
untrusted code 会抛出处理器异常,trustedcode可以通过执行STAC/CLAC指令来访问U-page
SEIMI的各项工作?
- 包括三个核心组件:内存管理,特权指令拦截和事件重定向
- 内存管理用来配置常规/隔离的内存区域,实现基于SMAP的隔离,相当于实现了传统OS的内存管理功能
- 特权指令拦截组件用来防止被攻击者滥用特权指令
- 事件重定向组件用于在进程通过system call/interrupts/exceptions访问内核时配置和拦截VM exits。在拦截到exits后将其交付给kernel进行处理。
Note
SEIMI要解决的问题:
- 现有的防御memory-corruption攻击的技术需要一个安全前提:高效的进程内的内存敏感数据的完整性和机密性保护。
- 现有的能够提供保存进程内内存敏感数据的技术:
- information hiding:分配一块随机地址,缺点是安全性不足
- address-based isolation:不受信任的代码发起的每一个内存访问都需要检查敏感数据是否在内存范围内。性能开销主要来源于边界检查,MPX
- domain-based isolation:主要依靠权限管理,trusted code发起访问时将被授予访问权限,并在访问之后撤销权限。主要的开销来源于授予和撤销内存访问的权限。MPK
- SEIMI基于SMAP
SEIMI是如何工作的?
- SEIMI使用SMAP来阻止来自privileged untrusted user code到user mode中的敏感数据的访问。
- 在privileged trusted code访问敏感数据时,SMAP被暂时关闭,并且在结束访问时重新启用SMAP。
- SMAP启动时,所有的向用户空间的内存访问都会抛出一个处理器异常。(SEIMI中的untrusted和trusted都是运行在ring 0级别,因此可以将敏感数据保存在用户空间来阻止访问)
- SMAP是线程私有的,因此在一个线程内暂时关闭SMAP不会影响到别的SMAP。
- 整个内存区域被分成两部分,一部分是U-page,另一部分是S-page,其中U-page是隔离区。trusted code通过STAC指令来关闭SMAP以访问U-page,访问后通过CLAC重新开启SMAP。
- 为了避免untrusted code在ring 0级别下运行污染内核,SEIMI在VMX root模式运行操作系统内核。target process在VMX non-root模式下运行。
SEIMI对于SMAP的使用带来了哪些问题?如何解决这些问题?
- 如何防止ring 0级别的用户代码污染内核?
- 使用硬件支持的虚拟化技术,将kernel运行在VT-x root模式。
- 用户代码运行在VT-x 非root模式,这样用户代码通过虚拟化技术实现了用户代码与kernel的隔离。
- 相关工作:Dune使用Intel VT-x使用户代码运行在特权级别,但是需要代码是trusted和安全地。
- 如何让untrusted code安全地运行在内核?
- 防止代码访问两种硬件资源:
- privileged data resources(page tables, etc)
- privileged instructions
- 将privileged data resources保存在VMX root模式,使用Intel VT-x来强制特权指令触发VM exits以陷入到VMX root模式,并在root模式下完成指令的执行,这样不会将特权硬件资源暴露给用户代码
- 对于特权指令,根据不同的分类使其执行无效化或禁止执行。
- 防止代码访问两种硬件资源:
- 如何防止ring 0级别的用户代码污染内核?
SMAP的作用?在SEIMI中是怎么用的?
- SMAP最初是用来防止内核在用户空间执行恶意代码,也就是说,不允许ring 0级别的代码触及到ring 3级别的数据?
- x86中,运行状态分成了两个模式:U-mode和S-mode,其中:
- S-mode是ring 0,U-mode是ring 3
- 根据页表项,内存页被分成了S-page和U-page.
- 在SMAP关闭之后,S-mode的代码才能够访问U-page
- S-mode的代码可以通过设置RFLAGS的AC标志位来开启或关闭对于U-page的访问权限。
- 使用STAC/CLAC特权指令切换SMAP比切换MPK更快
威胁模型:
- SEIMI的目标是为防御机制提供进程内的隔离区域。
- 目标程序拥有可以被攻击者利用而获得随机读写的能力的安全漏洞
- 程序本身不是恶意软件
- defense mechanism本身是安全的,因此破坏SEIMI的隔离性的前提是破坏defense mechanism
- defense mechanism在安全时可以保证SEIMI免受内存破坏攻击
- defense的安全性依赖于SEIMI的隔离性
- 什么是目标程序?是defense mechanism还是通常的应用程序?应该是通常的应用程序
- 我认为目标程序可以是untrusted code也可以是trusted code,其中isolated memory是为defense mechanism准备的,可以是用defense mechanism保护进程运行在VMX non root模式的ring 0级别下。
难点:
区分SMAP读和写:
- 基于共享内存的读写分离方式:
- 为同一块物理内存分配了两块虚拟内存,其中一块被配置为U-page,可以被读/写,另一块被配置为S-page,只能被读
- 按照前文的说法,U-page是user mode的页面,而S-page是supervisor mode的页面
- 如果trusted code需要修改敏感数据,那么在关闭SMAP后,才可以对U-page进行修改
- 如果trusted code只需要读,那么直接读对应的S-page即可
- 前面所说的通过关闭SMAP访问U-page实际上应该是写U-page,读敏感数据似乎并不需要通过SMAP,而只需要读S-page即可
阻止修改或泄露privileged data structures
借助于Intel 的VT-x技术
- 将privileged data structures和operations放到VMX root模式
- 使所有的事件(sys call、exceptions、interrupts)都触发VM exits以陷入到VMX root模式,即陷入内核,然后在root模式中执行这些指令
阻止滥用privileged hardware features
- 修改指令使其触发VM exits并停止执行
- 使指令的执行结果无效
- 抛出处理器异常,或使执行无效
系统结构
使用SEIMI的进程在VMX non-root ring 0级别运行,可以直接访问SMAP。其他的进程在VMX root ring 3级别运行
SEIMI的进程安排对内核透明,在执行从内核返回到target process时,SEIMI自动切换VMX模式
SEIMI模块包括三个主要模块:内存管理,privileged-instruction prevention,event redirection
内存管理:用来为target process配置常规的和隔离的内存,用于实现基于SMAP的隔离
- SEIMI没有在VMX non-root状态下运行的OS来管理内存,因此需要SEIMI来帮助guest管理页表
- what is guest? 我认为guest应该是在non-root下运行的targete process,host应该是在VMX 中运行的kernel和其他的用户进程
- guest和host是虚拟化中的概念,其中guest相当于客户机,host是宿主机,在SEIMI中,具体应该为guest是target process,运行在VMX non-root模式下,host运行在VMX root模式下。
- 用户空间的内存布局应该在guest和host的页表中是一样的
- guest的物理内存应该被host kernel直接管理
- SEIMI能够灵活配置guest虚拟内存空间中的U-page和S-page
- guest不能访问host的内存
- SEIMI只复制顶级页表的前256个页表项,将剩余的页表项清空,作为guest的PML4’页,下面三级页表guest与host共享
- 配置U-page和S-page.每个页表项都有一个U/S bit,用于判断页表项对应的是U-mode还是S-mode.如果所有的U/S bit都是1,那么对应的页是U-page,否则是S-page.
- 在host的页表中,所有的用户空间的内存页都是U-page.也就是说host不可直接写用户页。
- SEIMI直接拷贝了host的顶级页表,因此拷贝过来的page还是U-page.但是实际上guest应该能够直接访问大部分页表,只有隔离的区域才应该被配置为U-page.所以将0~254个页表项的U/Sbit均置0,这样前255个页表项都变成了S-page。第255个表项仍然保留为U-page,其指向的内存区域作为隔离区域。
- 也就是说,SEIMI将guest中的非隔离内存区域变为了S-page,而在host的页表中,依然是U-page
- 因为需要区分读和写,因此需要将同一块隔离区域分别映射为S-page和U-page,SEIMI将第254个页表项作为只读的S-page,映射到第255个表项所指的内存区域,这样就实现了隔离的U-page和S-page共享同一块内存。SEIMI再修改R/W位来实现S-page的只读。
- 所有的S-page都是只读的吗? 显然不是,应该只能被内核读写,而不能被user space 访问,在这篇论文中,应该指的是可以被VMX non root 模式下ring 0级别的代码访问,可以被VMX root模式下ring 0 级别的系统内核访问,而不能被VMX non-root模式下ring3 级别下的用户进程来访问。
- S-page和U-page是根据操作系统中固有的U/Sbit标志位来区分的
- trusted code 通常是kernel, 而untrusted code通常是user code
- 用户代码默认是无法访问S-page的?对哦,但是user code是放在ring0级别的,所以应该是可以访问S-page
- SEIMI没有在VMX non-root状态下运行的OS来管理内存,因此需要SEIMI来帮助guest管理页表
拦截特权指令:SEIMI需要拦截掉VMX non-root模式下ring 0级别的所有的特权指令及其对privileged hardware features的访问
- 坦白说,我真的不知道是怎么实现的特权指令的拦截,可能类似于对于系统调用的hook?
- 找到所有的特权指令以及在ring 0 级别和ring 3级别表现不同的指令。
- 自动插入随机的操作数并在ring 3级别下运行
- 破坏指令的执行条件、触发VM exit
- 可以利用Intel的VT-x技术来让所有EXIT-Type的指令在VMX non-root模式下执行时触发VM eixts.
- 对于EXP-Type的指令,抛出不同类型的异常
- 抛出#UD:取消VMCS对这些指令的支持
- 抛出#GP:SEIMI不应该允许ring 0级别的应用程序修改任何段寄存器。即不允许ring 0状态下的指令切换段
- 观察到修改段寄存器时,硬件将会使用target selector来访问段描述符表。如果段描述符表为空,CPU将会抛出#GP异常
- 如何确保在段描述符表为空时程序能够正确执行?如何确保与段相关的指令的正常工作?
- 每个段寄存器都有两个部分,一个可见部分用于段选择符,另一个不可见的部分用于描述符缓存。
- 在执行不切换段的指令时,硬件直接从描述符缓存中读取数据,只有当指令切换段时,硬件才会访问段描述符表并把目标段的信息加载到cache中。段选择符用于访问段描述符表。
- 因此将正确的段描述符信息存放在描述符cache中,并且将段描述符表清空。在VMCS的 guest-state字段存放选择器和段描述符的内容。
- 在进入VMX non-root模式时,信息将会被直接加载到guest segment register,然后把GDTR和LDTR寄存器的base和limit字段设置为0.这样不会影响到不切换段的指令的执行,而会在切换段的指令执行时抛出异常。
- SEIMI捕获异常后检查操作是否合法,如果合法SEIMI将请求的段信息存放到VMCS的段寄存器中并且返回到VMX non-root模式。合法是指的程序应该在ring 3级别下访问而不是在ring 0级别下访问。但是程序不是在ring 0级别下运行的吗
- 抛出#PF: SYSEXIT/SYSRET将会切换段并且向描述符缓存中填充固定的值而不需要访问描述符表,因此不会抛出#GP异常。
- 但是SYSEXIT/SYSRET指令将会导致权限切换到ring 3,而这时ring 3级别的进程将无法访问S-page(note:内存管理时前面的255个page都是S-page,只能由ring 0级别的进程访问。剩下的是U-page,这个可以访问。)。因此当CPU执行下一条指令时将会抛出异常。我明白了,U-page中保存的是敏感数据,而指令保存在S-page中,切换到ring 3后,CPU将无法访问下一条指令
使指令的执行无效:对于INV-Type类型的指令,使这些指令无效化
- 什么叫使指令无效化?
- 与CR*寄存器相关的指令:
- Intel VT-x技术允许通过配置VMCS来控制这些指令的执行。VMCS中的CR0和CR4寄存器有guest/host 掩码和read shadows。guest/host掩码中的每个bit指明了CR0/CR4中相对应bit的所有权——0为guest,1为host。SEIMI将所有的mask设置为1,read shadows所有的位为0.
- 这样从寄存器中读到的数据始终为0,而写将不会修改寄存器的值。
- CR2寄存器用于在#PF异常出现时保存错误的地址,#PF将会直接触发VM exitts,并且地址保存在VMCS上,因此CR2实际上没有任何作用。
- SWAPGS用来快速交换GS和IA32_KERNEL_GS_BASE MSR寄存器中的值,SEIMI将两个寄存器中的值始终保持相同,因此SWAPGS毫无意义
- LAR和LSL指令用来获取访问权限,VERR和VERW用来验证一个段是否可读可写,前面已经将所有的段描述符表清空,因此这几条指令将会因此descriptor load segment violation,RFLAG.ZF标志位将被设置为0。SEIMI将会忽略掉这些指令
- CLI/STI可以修改系统的标志位IF,POPF/POPFQ可以用来修改IOPL和AC。
- IF标志位用来屏蔽硬件中断,IOPL用来控制I/O相关指令的条件执行
- SEIMI中修改IF和IOPL没有作用因为中断和I/O指令将会触发无条件的VM exits。
- 如何消除POPFQ在AC上的影响?
- 在POPFQ之前插入一条and指令,因此stack对象的AC标志位将永远是0。
- 同时在威胁模型中,攻击者不能劫持控制流,因此无法跳过and
重定向和交付内核处理程序
- 系统调用处理:SYSCALL指令不能实现控制流从VMX non-root或VMX root模式的转换。
- 通过将代码页映射到目标内存空间,来使用VMCALL替换SYSCALL。