
LLVM要求输入代码为SSA形式,那么什么是SSA以及如何利用LLVM将拥有可变类型的代码转换为SSA形式?
SSA是IR的一种属性,要求每个变量仅被赋值一次并在被使用前定义。在初始的IR中已经存在的变量被划分为不同的版本,新的变量通常由原始名称和下标表示,因此每个定义实际上都有自己的不同版本。在SSA中,use-def链是显式的,并且每个链都包含一个单独的变量。
use-def链是一种特殊的数据结构:其中包含了一次定义和若干次使用,用于静态程序分析如数据流分析、可达性分析等中。use-def链是很多编译器优化的前置条件,包括常量传播和公共子表达式消除等。
SSA的优点在于可以通过简化变量的属性来同时简化和提高编译器优化的效果。例如:
1
2
3
y := 1
y := 2
x := y
通过SSA可以表达为如下的形式:
1
2
3
y.1 = 1
y.2 = 1
x.1 = y.2
因此可以在优化时将y:=1这一并没有被使用到的赋值消除。
Converting to SSA
将普通代码转换为SSA形式主要是将每个赋值目标替换为一个新的变量,并将其每次使用替换为该点对应的变量的版本:
例如将下图所示的控制流图转换为SSA表示:
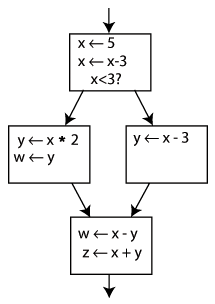
将x<-x-3替换为x.2 <- x.1-3,并将对应的版本扩散到所有的基本块中,可以得到如下的SSA表示:
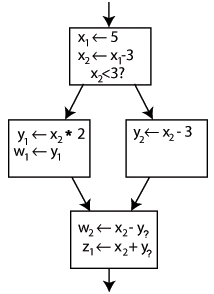
可以看到在上层的三个基本块中,可以根据变量名和版本非常容易地追溯到每个变量定义和修改的位置,但是在底部的基本块中,由于前面出现了分支指令,因此w.2中使用的y的值取决于执行时选择了哪一条执行路径。为了解决这个问题,在基本块中引入了一条新的指令,称为Phi函数。Phi函数的作用是根据之前的控制流来选择y.1或y.2用以生成y.3的定义,引入Phi函数后的控制流图如下所示:

大多数机器都没有实现与Phi函数对应的特殊指令,因此通常由编译器通过在每个预处理块后插入move指令来实现。例如,在上例中,编译器必须在左侧block的末尾添加从y.1到y.3的move指令,在右侧block的末尾添加从y.2到y.3的move指令。
Computing minimal SSA using dominance frontiers
对于任意给定的控制流图,通常采用dominance frontiers方法来选择插入Phi函数的位置。
首先需要定义dominator的概念:如果任何到达节点B的执行路径都必须首先经过节点A,那么就称节点A严格控制节点B。如果A严格控制B或A = B,那么就说A控制B(B被A控制)。并且通过严格控制,我们可以得到如下结论:如果当前指令执行到了B,那么节点A中的指令必然已经全部执行完毕。
接下来定义dominance frontier:如果A没有严格控制B,但是控制了一些B的直接前驱,或A是B的直接前驱,并且由于任何节点控制其自身,那么我们称节点B在A的dominance frontier中。从节点A的角度来看,这些节点是其他不经过A的控制路径中最早出现的节点。
dominance frontier给出了需要插入Phi函数的位置:如果节点A定义了某个变量,那么该定义将会传播到被A控制的每个结点。只有当离开了这些被控制的结点并进入了dominance frontier时,才需要插入Phi指令来不同的控制流选择变量的版本。
LLVM 中生成Phi函数
在LLVM Kaleidoscope中给出了一个控制流图的实例:
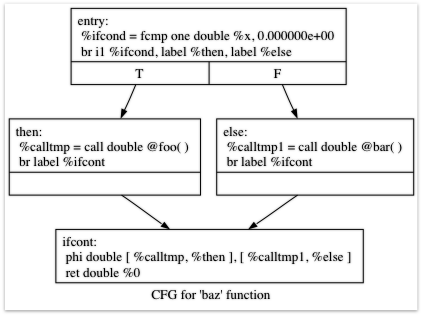
需要将对应的if/then/else基本块转换为LLVM IR指令。在then和else两个分支执行完后重新回到ifcont这个block来继续执行后续的指令,在这个示例中需要根据前面控制流的执行情况来判断调用的函数,因此如前所述需要引入Phi函数来实现SSA。
在实践中,实际上只有两种情况需要使用Phi结点:
- 使用了用户变量的代码:x = 1; x = x + 1;
- 在AST结构中隐含的值,例如上例中的IfExprAST节点类,其中隐含了If/Then/Else三种block
LLVM IR for AST(If/Then/Else)
对于第二类情况,可以直接插入Phi结点,在上例中,使用llvm生成If/then/else block对应的IR,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// 获得要生成If/then/else block的函数
llvm::Function *TheFunction = Builder.GetInsertBlock()->getParent();
// 为then和else block创建block,并在TheFuntion后插入then block。
llvm::BasicBlock *ThenBB = llvm::BasicBlock::Create(TheContext, "then", TheFunction);
// 因为CreateBlock并没有隐式修改Builder, 因此else block不能直接插入到TheFunction后
llvm::BasicBlock *ElseBB = llvm::BasicBlock::Create(TheContext, "else");
// ifcont block
llvm::BasicBlock *MergeBB = llvm::BasicBlock::Create(TheContext, "ifcont");
// 创建跳转到ThenBB和ElseBBd的分支
Builder.CreateCondBr(CondV, ThenBB, ElseBB);
// 在创建条件分支被插入后,移动Builder来开始ThenBB, 即then block,更确切的说,Builder.SetInsertPoint(ThenBB)将指向插入位置的指针移动到ThenBB的末尾。
Builder.SetInsertPoint(ThenBB);
// 生成Then block的代码
llvm::Value *ThenV = Then->codegen();
if (!ThenV)
return nullptr;
// 为了结束then block,创建一个无条件分支到merge block,即MergeBB.
Builder.CreateBr(MergeBB);
// Then->codegen会改变当前的block,因此需要更新ThenBB
ThenBB = Builder.GetInsertBlock();
// Else block与then block基本一致
// Emit else block
TheFunction->getBasicBlockList().push_back(ElseBB);
Builder.SetInsertPoint(ElseBB);
llvm::Value *ElseV = Else->codegen();
if (!ElseV)
return nullptr;
Builder.CreateBr(MergeBB);
ElseBB = Builder.GetInsertBlock();
// 生成MergeBB
TheFunction->getBasicBlockList().push_back(MergeBB);
// 设置插入点为MergeBB, 后续新创建的代码将会被加入到MergeBB中
Builder.SetInsertPoint(MergeBB);
llvm::PHINode *PN = Builder.CreatePHI(llvm::Type::getDoubleTy(TheContext), 2, "iftmp");
PN->addIncoming(ThenV, ThenBB);
PN->addIncoming(ElseV, ElseBB);
return PN;
!注意:llvm IR需要所有的基本块以一个控制流指令结尾,例如return或branch指令,这意味着LLVM IR中所有的控制流指令都需要显式创建,否则verifier将会抛出一个错误。例如上例中的 Builder.CreateBr(MergeBB);
LLVM IR for mutable variables
首先,理解mutable variable在转换为SSA形式时出现的问题,考虑如下代码:
1
2
3
4
5
6
7
8
9
int G, H;
int test(_Bool Condition) {
int X;
if (Condition)
X = G;
else
X = H;
return X;
}
最终返回的X的值取决于条件分支的转移路径,因此需要使用Phi函数来合并两个不同的值,与上面C代码对应的LLVM IR如下所示:
@G = weak global i32 0 ; type of @G is i32*
@H = weak global i32 0 ; type of @H is i32*
define i32 @test(i1 %Condition) {
entry:
br i1 %Condition, label %cond_true, label %cond_false
cond_true:
%X.0 = load i32, i32* @G
br label %cond_next
cond_false:
%X.1 = load i32, i32* @H
br label %cond_next
cond_next:
%X.2 = phi i32 [ %X.1, %cond_false ], [ %X.0, %cond_true ]
ret i32 %X.2
}
与LLVM IR for AST的不同在于,在两个不同的分支中,只有变量X的值被改变,而AST的CFG中涉及了过程间跳转。
LLVM要求寄存器以SSA形式来使用,但对于内存对象并没有要求。LLVM中使用Analysis Pass来处理对于内存数据流的分析。LLVM中所有的内存访问都通过显式的load/store指令来实现,并且并不需要address-of操作符。@G和@H的类型为i32 *,这意味着@G在全局数据空间中为@G分配了一块i32大小的空间,但是其名字@G实际上指向的是这块空间的地址。栈变量的定义方式相同,区别仅在于全局变量定义在全局数据空间中,栈变量通过alloca指令来定义,例如:
define i32 @example() {
entry:
%X = alloca i32 ; type of %X is i32*.
...
%tmp = load i32, i32* %X ; load the stack value %X from the stack.
%tmp2 = add i32 %tmp, 1 ; increment it
store i32 %tmp2, i32* %X ; store it back
...
通过alloca定义的栈变量比寄存器更加灵活,例如可以将栈变量的地址作为参数传递给函数或是用于保存其他变量。通过使用alloca可以避免对于Phi的使用:
@G = weak global i32 0 ; type of @G is i32*
@H = weak global i32 0 ; type of @H is i32*
define i32 @test(i1 %Condition) {
entry:
%X = alloca i32 ; type of %X is i32*.
br i1 %Condition, label %cond_true, label %cond_false
cond_true:
%X.0 = load i32, i32* @G
store i32 %X.0, i32* %X ; Update X
br label %cond_next
cond_false:
%X.1 = load i32, i32* @H
store i32 %X.1, i32* %X ; Update X
br label %cond_next
cond_next:
%X.2 = load i32, i32* %X ; Read X
ret i32 %X.2
}
通过使用alloca,我们发现了一种可以处理任意的可变变量而不需要创建Phi结点的方式。
- 将每个可变变量的定义变为在栈上分配内存
- 变量的每次读改为load指令
- 变量的每次写改为store指令
- 取变量地址直接使用变量名
但是alloca带来了一个新的问题:之前对于寄存器的直接访问变为了对于内存的访问,从而会带来性能上的损失。LLVM optimizer提供了一个称为mem2reg的pass来将alloca提升为SSA寄存器,并在合适的地方插入Phi结点。mem2reg实现了标准的iterated dominance frontier 算法来构建SSA,mem2reg尽在满足如下条件的变量上起作用:
- mem2reg寻找alloca指令,并且判断对应的变量是否可以提升。对于全局变量或堆上的内存分配不起作用。
- mem2reg仅在函数入口块处查找alloca, 在入口块中保证了alloca仅仅执行一次,简化分析过程
- mem2reg仅提升对于变量的直接读写(e.g.对于变量名所指的直接地址的load和store),如果栈对象被传递给一个函数或出现了对于栈指针的算术运算,那么不会被mem2reg提升。
- mem2reg仅对所谓的first class (即指针、标量和向量等)values或长度为1的array生效,而不能将结构体或数组提升为寄存器。sroa pass可以提升结构体,union和数组。
LLVM for variables mutation
首先需要对函数的入口块创建alloca:
1
2
3
4
5
6
static llvm::AllocaInst *CreateEntryBlockAlloca(llvm::Function *TheFunction, const std::string &VarName) {
// 创建了一个指向函数入口第一条指令的IRBuilder
llvm::IRBuilder<> TmpB(&TheFunction->getEntryBlock(), TheFunction->getEntryBlock().begin());
// 创建名为VarName的变量的alloca指令,默认所有的变量类型均为double
return TmpB.CreateAlloca(llvm::Type::getDoubleTy(TheContext), 0, VarName.c_str());
}
同时对于变量的访问方式发生了改变:
1
2
3
4
5
6
7
8
9
10
11
12
// 在entry block中为变量创建alloca
llvm::AllocaInst *Alloca = CreateEntryBlockAlloca(TheFunction, VarName);
// 为start生成StartVal
llvm::Value *StartVal = Start->codegen();
if (!StartVal)
return nullptr;
// 将StartVal保存到Alloca中
Builder.CreateStore(StartVal, Alloca);
// 重新将alloca中保存的变量加载到寄存器
llvm::Value *CurVar = Builder.CreateLoad(Alloca);
添加mem2reg pass:
1
2
3
4
5
6
// 将alloca提升到寄存器
TheFPM->add(createPromoteMemoryToRegisterPass());
// peephole和bit-twiddling优化
TheFPM->add(createInstructionCombiningPass());
// Reassociate expressions.
TheFPM->add(createReassociatePass());