
System call tracing
实现系统调用trace,输入参数为一个int类型的mask,其中mask的某一位为1代表与该位对应的系统调用应该被trace。例如trace(1« SYS_fork)表示trace fork这一系统调用。被trace的系统调用输出:pid: syscall syscall_name -> return value。 首先在user/user.h中包含了当前系统中所有系统调用的声明,因此应该在该文件中添加trace的声明。user/目录下已经包含了trace.c这一命令的源文件,其中对于trace的调用为:
if (trace(atoi(argv[1])) < 0) {
fprintf(2, "%s: trace failed\n", argv[0]);
exit(1);
}
可以看出trace的返回值为int类型,在trace执行错误时返回负数,否则返回非负数。 因此在user.h中添加该系统调用的声明:
int trace(int);
在用户态调用该函数时,通过执行user/usys.S中与系统调用对应的命令从用户态切换到内核态以执行真正的系统调用处理函数:
trace:
li a7, SYS_trace
ecall
ret
其中第一行li a7, SYS_trace是设置系统调用号,第二行ecall陷入内核态,执行uservec、usertrap和syscall,第三行ret在系统调用执行完毕返回用户态后返回。SYS_trace是在kernel/syscall.h中定义的系统调用号:
#define SYS_trace 22
syscall函数定义在kernel/syscall.c中,通过myproc函数获得当前运行进程的proc结构体,通过读取a7寄存器获得需要执行的系统调用号,如果该系统调用号合法,则通过系统调用号获取对应的函数指针并执行,系统调用的返回值保存在a0寄存器中。我们在proc结构体中添加了trace_mask用于记录trace的mask参数,如果trace_mask & 1 « num不为0,则表示该系统调用应当被trace,输出对应的记录信息:
void syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num])
{
p->trapframe->a0 = syscalls[num]();
if ((p->trace_mask & (1 << num)) != 0)
{
printf("%d: syscall %s -> %d\n", p->pid, mapping(num), p->trapframe->a0);
}
}
else
{
printf("%d %s: unknown sys call %d\n", p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
每个系统调用函数定义在kernel/sysproc.c中,仿照其他的系统调用,参数通过argint来获得,形参设置为void:
uint64
sys_trace(void) {
struct proc *p = myproc();
if (argint(0, &p->trace_mask) < 0) {
return -1;
}
return 0;
}
在执行完trace这一系统调用后,trace.c随后调用了exec,相当于创建一个新的进程来执行被trace的后续命令,因此需要修改fork来传递trace进程的trace_mask值:
// user/trace.c
exec(nargv[0], nargv);
// kernel/proc.c
int
fork(void)
{
...
np->state = RUNNABLE;
np->trace_mask = p->trace_mask;
release(&np->lock);
...
}
最后执行trace的输出如下: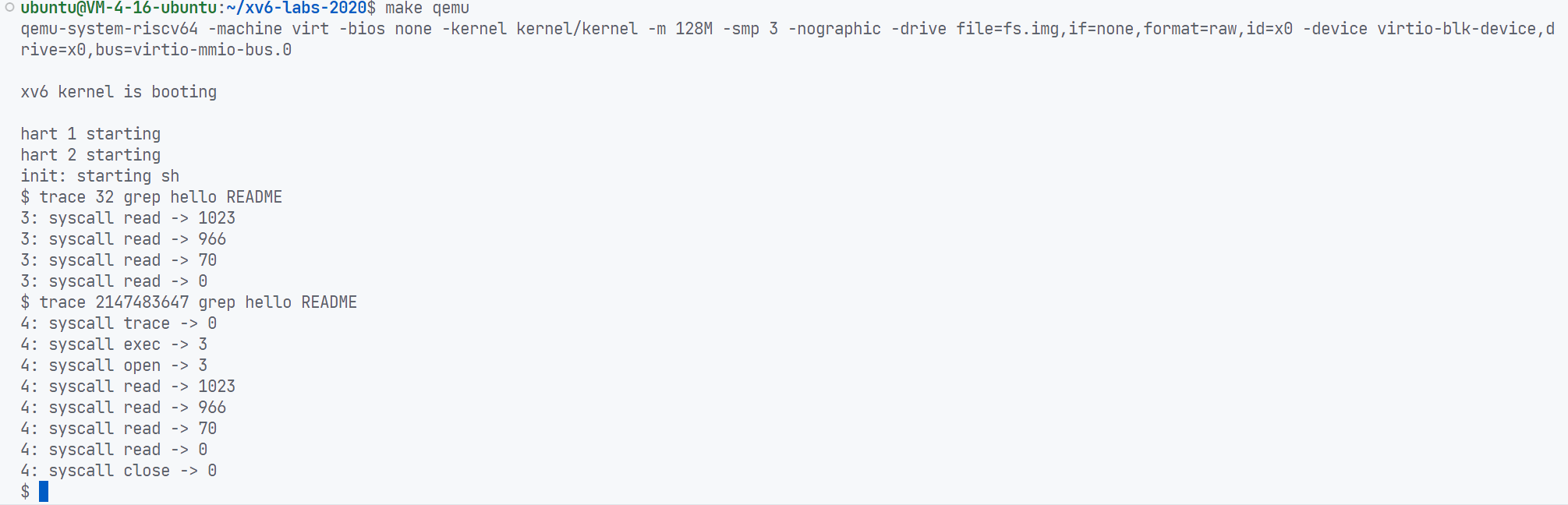
Sysinfo
实现系统调用sysinfo,收集来自运行时的系统信息。该系统调用以一个指向struct sysinfo类型的指针作为参数,返回系统剩余的内存大小和当前的进程数。 与上面的trace类似,首先添加用户态的系统调用声明:
int sysinfo(struct sysinfo *);
随后在kernel/syscall.h添加SYS_sysinfo对应的系统调用号:
#define SYS_sysinfo 23
在kernel/sysproc.c中添加sysinfo系统调用处理函数的定义:
uint64
sys_sysinfo(void) {
uint64 st;
struct sysinfo info;
if (argaddr(0, &st) < 0)
return -1;
info.nproc = proccount();
info.freemem = freemem();
struct proc *p = myproc();
if (copyout(p->pagetable, st, (char *)&info, sizeof(info)))
return -1;
return 0;
}
其中通过argaddr获取传入的sysinfo指针指向的地址,通过proccount和freemem两个函数设置info的nproc和freemem两个字段,然后通过copyout将info拷贝到传入参数所指向的sysinfo中。copyout的定义为:
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len);
作用是从src拷贝len个字节到进程虚拟地址dstva中,而dstva通过进程页表pagetable转换到对应的物理地址。
proccount
在kernel/proc.c中定义proccount函数来返回系统中的进程数:
uint64
proccount(void) {
uint64 cnt = 0;
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
if (p->state == UNUSED)
continue;
cnt++;
}
return cnt;
}
xv6内核中所有的进程组织为struct proc类型的数组,数组长度固定为64,在通过allocproc来创建新的进程时遍历proc数组找到第一个状态为UNUSED的进程初始化为新进程。因此在计数系统中非空闲的进程时,只需要遍历整个proc数组,依次判断类型是否为UNUSED,如果不是UNUSED则计数+1。
freemem
在kernel/kalloc.c中添加freemem函数来计算当前的剩余空间:
uint64
freemem(void) {
struct run *r;
uint64 cnt = 0;
acquire(&kmem.lock);
r = kmem.freelist;
while (r)
{
cnt += PGSIZE;
r = r->next;
}
release(&kmem.lock);
return cnt;
}
xv6空闲内存以链表的形式组织,定义为kmem:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
kmem的第一个字段为自旋锁,保证在一个时间点只有一个进程访问kmem。第二个字段为freelist,即当前空余的页组成的链表。 在kalloc函数中分配内存时,首先通过acquire获取锁,然后从freelist中获得一个空闲的节点,然后释放锁,再通过memset初始化分配的页:
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
memset的第三个参数为PGSIZE,也就是说每个空闲节点对应的内存大小为PGSIZE个字节,因此在freemem中遇到的每个freelist使计数+PGSIZE。
最后通过测试:
